
Homepage
Contact

Dr. Marc Habermann
Max-Planck-Institut für InformatikDepartment 6: Visual Computing and Artificial Intelligence
| position: | Tenured Senior Researcher / Scientific Manager of the Real Virtual Lab |
| office: |
Campus E1 4,
Room 216 Saarland Informatics Campus 66123 Saarbrücken Germany |
| email: | mhaberma@mpi-inf.mpg.de |
| phone: | +49 681 9325-4507 |
| fax: | +49 681 9325-4099 |
| Google Scholar |
Research Interests
I am a senior researcher at the Max Planck Institute for Informatics where I head the Graphics and Vision for Digital Humans group.
My research interests lie in the field of Computer Vision, Computer Graphics, and
Machine Learning. In particular, my work focuses on real-time human performance capture from single
RGB videos, physical plausibility of the surface deformations and the human motion, photo-realistic
animation synthesis, and learning generative 3D human characters from video.
In summary, my research interests include (but are not limited to):
- Computer Vision, Computer Graphics, Machine Learning
- Human Performance Capture and Synthesis
- Reconstruction of Non-Rigid Deformations from RGB Video
- Neural Rendering
- Motion Capture
Invited Talks/News
- 2025-05-16 Marc Habermann was appointed a Saarland University Associate Fellow.
- 2025-05-12 Joint Tutorial on Virtual Humans meet Event-based and Quantum-enhanced Vision @ Eurographics 2025 [conference]
- 2024-10-16 We got featured by Spektrum der Wissenschaft! [arcticle]
- 2024-09-10 Joint Tutorial on Virtual Humans and Quantum-enhanced Vision @ GCPR/VMV 2024 [conference]
- 2023-05-03 Digital Humans @ Saarland Informatics Campus Lecture Series [video]
- 2022-07-11 Human Performance Capture and Synthesis @ Adobe [video]
- 2021-09-28 Real-time Deep Dynamic Characters @ Google Zuerich [video]
- 2020-10-29 DeepCap @ Computer Vision Reading Group EPFL [video]
Pre-prints
 |
Second-order Optimization of Gaussian Splats with Importance Sampling
Hamza Pehlivan
Andrea Boscolo Camiletto
Lin Geng Foo
Marc Habermann
Christian Theobalt
arxiv 2025
Abstract3D Gaussian Splatting (3DGS) is widely used for novel view synthesis due to its high rendering quality and fast inference time. However, 3DGS predominantly relies on first-order optimizers such as Adam, which leads to long training times. To address this limitation, we propose a novel second-order optimization strategy based on Levenberg-Marquardt (LM) and Conjugate Gradient (CG), which we specifically tailor towards Gaussian Splatting. Our key insight is that the Jacobian in 3DGS exhibits significant sparsity since each Gaussian affects only a limited number of pixels. We exploit this sparsity by proposing a matrix-free and GPU-parallelized LM optimization. To further improve its efficiency, we propose sampling strategies for both the camera views and loss function and, consequently, the normal equation, significantly reducing the computational complexity. In addition, we increase the convergence rate of the second-order approximation by introducing an effective heuristic to determine the learning rate that avoids the expensive computation cost of line search methods. As a result, our method achieves a 3× speedup over standard LM and outperforms Adam by 6× when the Gaussian count is low while remaining competitive for moderate counts.
|
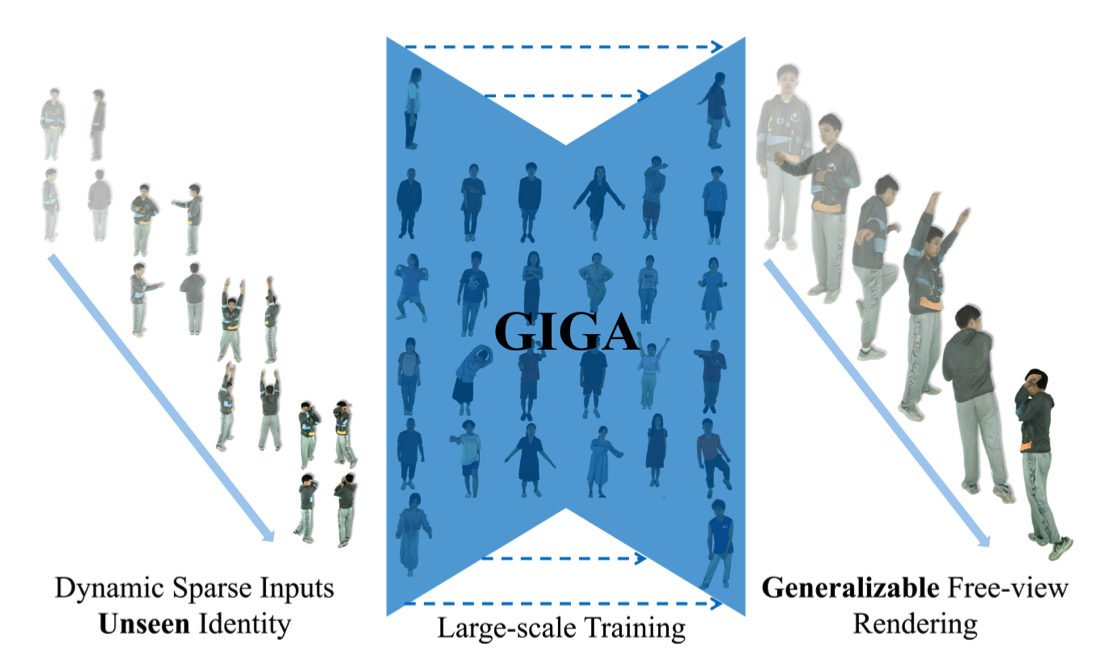 |
GIGA: Generalizable Sparse Image-driven Gaussian Avatars
Anton Zubekhin
Heming Zhu
Paulo Gotardo
Thabo Beeler
Marc Habermann
Christian Theobalt
arxiv 2025
AbstractDriving a high-quality and photorealistic full-body human avatar, from only a few RGB cameras, is a challenging problem that has become increasingly relevant with emerging virtual reality technologies. To democratize such technology, a promising solution may be a generalizable method that takes sparse multi-view images of an unseen person and then generates photoreal free-view renderings of such identity. However, the current state of the art is not scalable to very large datasets and, thus, lacks in diversity and photorealism. To address this problem, we propose a novel, generalizable full-body model for rendering photoreal humans in free viewpoint, as driven by sparse multi-view video. For the first time in literature, our model can scale up training to thousands of subjects while maintaining high photorealism. At the core, we introduce a MultiHeadUNet architecture, which takes sparse multi-view images in texture space as input and predicts Gaussian primitives represented as 2D texels on top of a human body mesh. Importantly, we represent sparse-view image information, body shape, and the Gaussian parameters in 2D so that we can design a deep and scalable architecture entirely based on 2D convolutions and attention mechanisms. At test time, our method synthesizes an articulated 3D Gaussian-based avatar from as few as four input views and a tracked body template for unseen identities. Our method excels over prior works by a significant margin in terms of cross-subject generalization capability as well as photorealism.
|
Publications
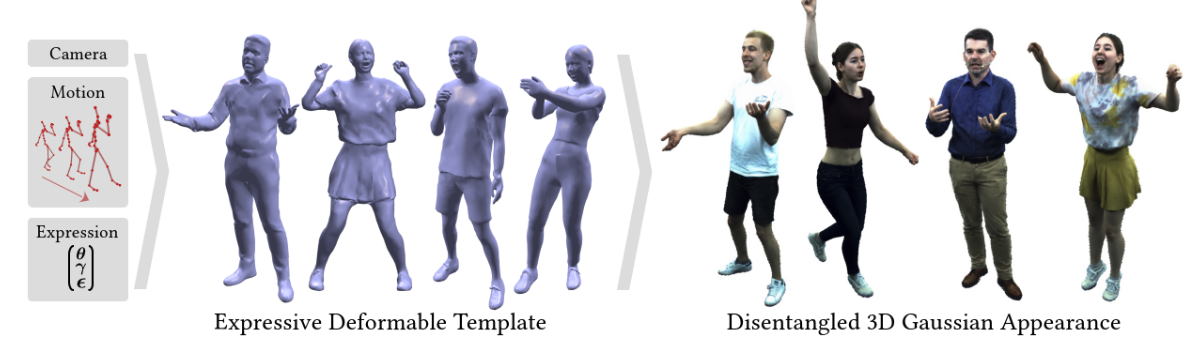 |
EVA: Expressive Virtual Avatars from Multi-view Videos
Hendrik Junkawitsch
Guoxing Sun
Heming Zhu
Christian Theobalt
Marc Habermann
Siggraph 2025
AbstractWith recent advancements in neural rendering and motion capture algorithms, remarkable progress has been made in photorealistic human avatar modeling, unlocking immense potential for applications in virtual reality, augmented reality, remote communication, and industries such as gaming, film, and medicine. However, existing methods fail to provide complete, faithful, and expressive control over human avatars due to their entangled representation of facial expressions and body movements. In this work, we introduce Expressive Virtual Avatars (EVA), an actor-specific, fully controllable, and expressive human avatar framework that achieves high-fidelity, lifelike renderings in real time while enabling independent control of facial expressions, body movements, and hand gestures. Specifically, our approach designs the human avatar as a two-layer model: an expressive template geometry layer and a 3D Gaussian appearance layer. First, we present an expressive template tracking algorithm that leverages coarse-to-fine optimization to accurately recover body motions, facial expressions, and non-rigid deformation parameters from multi-view videos. Next, we propose a novel decoupled 3D Gaussian appearance model designed to effectively disentangle body and facial appearance. Unlike unified Gaussian estimation approaches, our method employs two specialized and independent modules to model the body and face separately. Experimental results demonstrate that EVA surpasses state-of-the-art methods in terms of rendering quality and expressiveness, validating its effectiveness in creating full-body avatars. This work represents a significant advancement towards fully drivable digital human models, enabling the creation of lifelike digital avatars that faithfully replicate human geometry and appearance.
|
 |
FRAME: Floor-aligned Representation for Avatar Motion from Egocentric Video
Andrea Boscolo Camiletto
Jian Wang
Eduardo Alvarado
Rishabh Dabral
Thabo Beeler
Marc Habermann
Christian Theobalt
CVPR 2025
Poster Highlight (13.5% of accepted papers)
AbstractEgocentric motion capture with a head-mounted body-facing stereo camera is crucial for VR and AR applications but presents significant challenges such as heavy occlusions and limited annotated real-world data. Existing methods rely on synthetic pretraining and struggle to generate smooth and accurate predictions in real-world settings, particularly for lower limbs. Our work addresses these limitations by introducing a lightweight VR-based data collection setup with on-board, real-time 6D pose tracking. Using this setup, we collected the most extensive real-world dataset for ego-facing ego-mounted cameras to date in size and motion variability. Effectively integrating this multimodal input -- device pose and camera feeds -- is challenging due to the differing characteristics of each data source. To address this, we propose FRAME, a simple yet effective architecture that combines device pose and camera feeds for state-of-the-art body pose prediction through geometrically sound multimodal integration and can run at 300 FPS on modern hardware. Lastly, we showcase a novel training strategy to enhance the model's generalization capabilities. Our approach exploits the problem's geometric properties, yielding high-quality motion capture free from common artifacts in prior works. Qualitative and quantitative evaluations, along with extensive comparisons, demonstrate the effectiveness of our method.
|
 |
Thin-Shell-SfT: Fine-Grained Monocular Non-rigid 3D Surface Tracking with Neural Deformation Fields
Navami Kairanda
Marc Habermann
Shanthika Naik
Christian Theobalt
Vladislav Golyanik
CVPR 2025
Abstract3D reconstruction of highly deformable surfaces (e.g. cloths) from monocular RGB videos is a challenging problem, and no solution provides a consistent and accurate recovery of fine-grained surface details. To account for the ill-posed nature of the setting, existing methods use deformation models with statistical, neural, or physical priors. They also predominantly rely on nonadaptive discrete surface representations (e.g. polygonal meshes), perform frame-by-frame optimisation leading to error propagation, and suffer from poor gradients of the mesh-based differentiable renderers. Consequently, fine surface details such as cloth wrinkles are often not recovered with the desired accuracy. In response to these limitations, we propose ThinShell-SfT, a new method for non-rigid 3D tracking that represents a surface as an implicit and continuous spatiotemporal neural field. We incorporate continuous thin shell physics prior based on the Kirchhoff-Love model for spatial regularisation, which starkly contrasts the discretised alternatives of earlier works. Lastly, we leverage 3D Gaussian splatting to differentiably render the surface into image space and optimise the deformations based on analysis-bysynthesis principles. Our Thin-Shell-SfT outperforms prior works qualitatively and quantitatively thanks to our continuous surface formulation in conjunction with a specially tailored simulation prior and surface-induced 3D Gaussians.
|
 |
RePerformer: Immersive Human-centric Volumetric Videos from Playback to
Photoreal Reperformance
Yuheng Jiang
Zhehao Shen
Chengcheng Guo
Yu Hong
Zhuo Su
Yingliang Zhang
Marc Habermann
Lan Xu
CVPR 2025
AbstractHuman-centric volumetric videos offer immersive free-viewpoint experiences, yet existing methods focus either on replaying general dynamic scenes or animating human avatars, limiting their ability to re-perform general dynamic scenes. In this paper, we present RePerformer, a novel Gaussian-based representation that unifies playback and re-performance for high-fidelity human-centric volumetric videos. Specifically, we hierarchically disentangle the dynamic scenes into motion Gaussians and appearance Gaussians which are associated in the canonical space. We further employ a Morton-based parameterization to efficiently encode the appearance Gaussians into 2D position and attribute maps. For enhanced generalization, we adopt 2D CNNs to map position maps to attribute maps, which can be assembled into appearance Gaussians for high-fidelity rendering of the dynamic scenes. For re-performance, we develop a semantic-aware alignment module and apply deformation transfer on motion Gaussians, enabling photo-real rendering under novel motions. Extensive experiments validate the robustness and effectiveness of RePerformer, setting a new benchmark for playback-then-reperformance paradigm in human-centric volumetric videos.
|
 |
BimArt: A Unified Approach for the Synthesis of 3D Bimanual Interaction with Articulated Objects
Wanyue Zhang
Rishabh Dabral
Vladislav Golyanik
Vasileios Choutas
Eduardo Alvarado
Thabo Beeler
Marc Habermann
Christian Theobalt
CVPR 2025
AbstractWe present BimArt, a novel generative approach for synthesizing 3D bimanual hand interactions with articulated objects. Unlike prior works, we do not rely on a reference grasp, a coarse hand trajectory, or separate modes for grasping and articulating. To achieve this, we first generate distance-based contact maps conditioned on the object trajectory with an articulation-aware feature representation, revealing rich bimanual patterns for manipulation. The learned contact prior is then used to guide our hand motion generator, producing diverse and realistic bimanual motions for object movement and articulation. Our work offers key insights into feature representation and contact prior for articulated objects, demonstrating their effectiveness in taming the complex, high-dimensional space of bimanual hand-object interactions. Through comprehensive quantitative experiments, we demonstrate a clear step towards simplified and high-quality hand-object animations that excel over the state-of-the-art in motion quality and diversity.
|
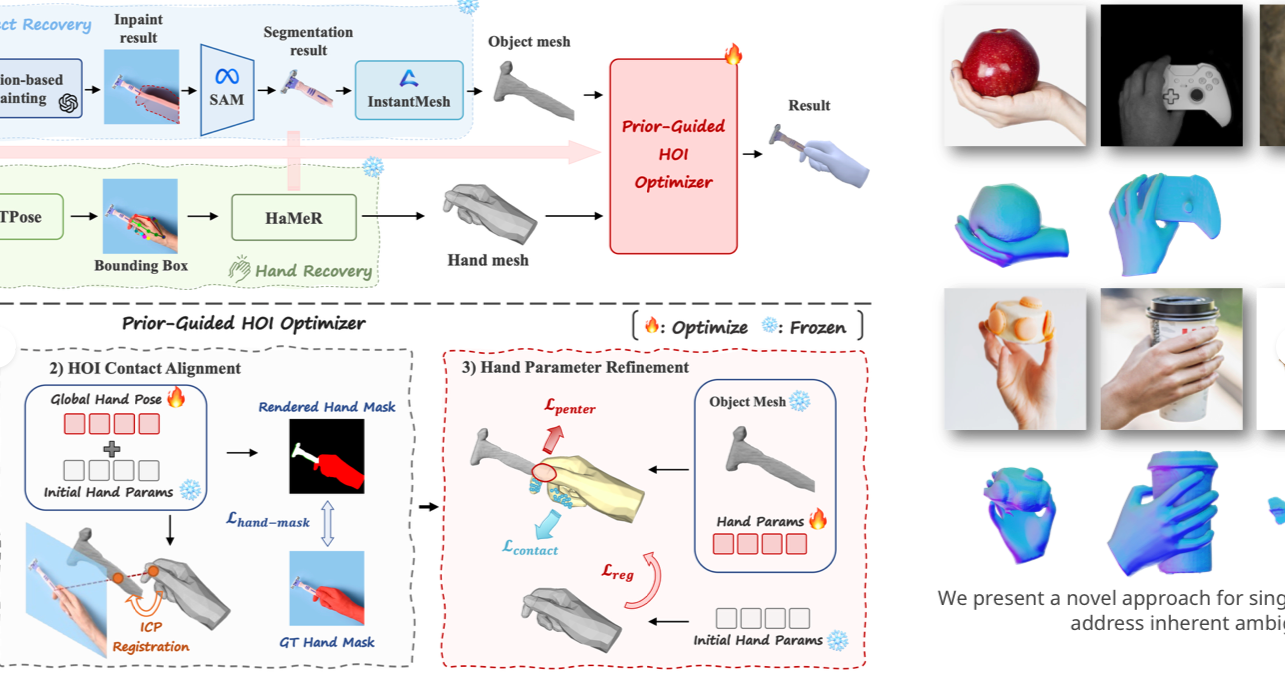 |
EasyHOI: Unleashing the Power of Large Models for Reconstructing Hand-Object Interactions in the Wild
Yumeng Liu
Xiaoxiao Long
Zeming Yang
Yuan Liu
Marc Habermann
Christian Theobalt
Yuexin Ma
Wenping Wang
CVPR 2025
AbstractOur work aims to reconstruct hand-object interactions from a single-view image, which is a fundamental but ill-posed task. Unlike methods that reconstruct from videos, multi-view images, or predefined 3D templates, single-view reconstruction faces significant challenges due to inherent ambiguities and occlusions. These challenges are further amplified by the diverse nature of hand poses and the vast variety of object shapes and sizes. Our key insight is that current foundational models for segmentation, inpainting, and 3D reconstruction robustly generalize to in-the-wild images, which could provide strong visual and geometric priors for reconstructing hand-object interactions. Specifically, given a single image, we first design a novel pipeline to estimate the underlying hand pose and object shape using off-the-shelf large models. Furthermore, with the initial reconstruction, we employ a prior-guided optimization scheme, which optimizes hand pose to comply with 3D physical constraints and the 2D input image content. We perform experiments across several datasets and show that our method consistently outperforms baselines and faithfully reconstructs a diverse set of hand-object interactions.
|
 |
Real-time Free-view Human Rendering from Sparse-view RGB Videos using
Double Unprojected Textures
Guoxing Sun
Rishabh Dabral
Heming Zhu
Pascal Fua
Christian Theobalt
Marc Habermann
CVPR 2025
Poster Highlight (13.5% of accepted papers)
Abstract
Real-time free-view human rendering from sparse-view RGB inputs is a challenging task due to the sensor scarcity and the tight time budget. To ensure efficiency, recent methods leverage 2D CNNs operating in texture space to learn rendering primitives. However, they either jointly learn geometry and appearance, or completely ignore sparse image information for geometry estimation, significantly harming visual quality and robustness to unseen body poses. To address these issues, we present Double Unprojected Textures, which at the core disentangles coarse geometric deformation estimation from appearance synthesis, enabling robust and photorealistic 4K rendering in real-time. Specifically, we first introduce a novel image-conditioned template deformation network, which estimates the coarse deformation of the human template from a first unprojected texture. This updated geometry is then used to apply a second and more accurate texture unprojection. The resulting texture map has fewer artifacts and better alignment with input views, which benefits our learning of finer-level geometry and appearance represented by Gaussian splats. We validate the effectiveness and efficiency of the proposed method in quantitative and qualitative experiments, which significantly surpasses other state-of-the-art methods.
|
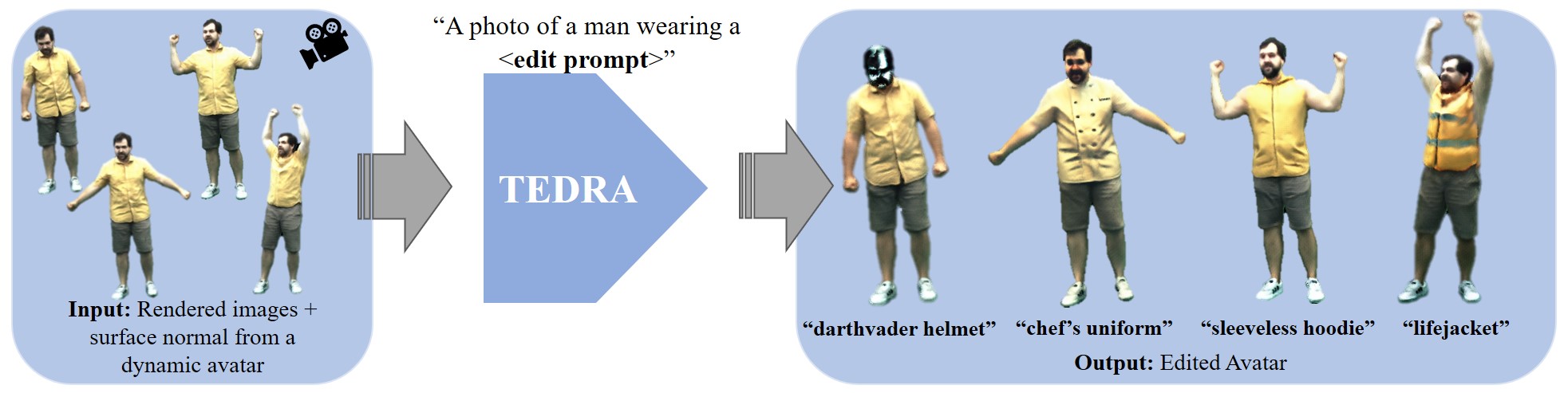 |
TEDRA: Text-based Editing of Dynamic and Photoreal Actors
Basavaraj Sunagad
Heming Zhu
Mohit Mendiratta
Adam Kortylewski
Christian Theobalt
Marc Habermann
3DV 2025
AbstractOver the past years, significant progress has been made in creating photorealistic and drivable 3D avatars solely from videos of real humans. However, a core remaining challenge is the fine-grained and user-friendly editing of clothing styles by means of textual descriptions. To this end, we present TEDRA, the first method allowing text-based edits of an avatar, which maintains the avatar's high fidelity, space-time coherency, as well as dynamics, and enables skeletal pose and view control. We begin by training a model to create a controllable and high-fidelity digital replica of the real actor. Next, we personalize a pretrained generative diffusion model by fine-tuning it on various frames of the real character captured from different camera angles, ensuring the digital representation faithfully captures the dynamics and movements of the real person. This two-stage process lays the foundation for our approach to dynamic human avatar editing. Utilizing this personalized diffusion model, we modify the dynamic avatar based on a provided text prompt using our Personalized Normal Aligned Score Distillation Sampling (PNA-SDS) within a model-based guidance framework. Additionally, we propose a time step annealing strategy to ensure high-quality edits. Our results demonstrate a clear improvement over prior work in functionality and visual quality.
|
 |
PocoLoco: A Point Cloud Diffusion Model of Human Shape in Loose Clothing
Siddharth Seth
Rishabh Dabral
Diogo Luvizon
Marc Habermann
Ming-Hsuan Yang
Christian Theobalt
Adam Kortylewski
WACV 2025
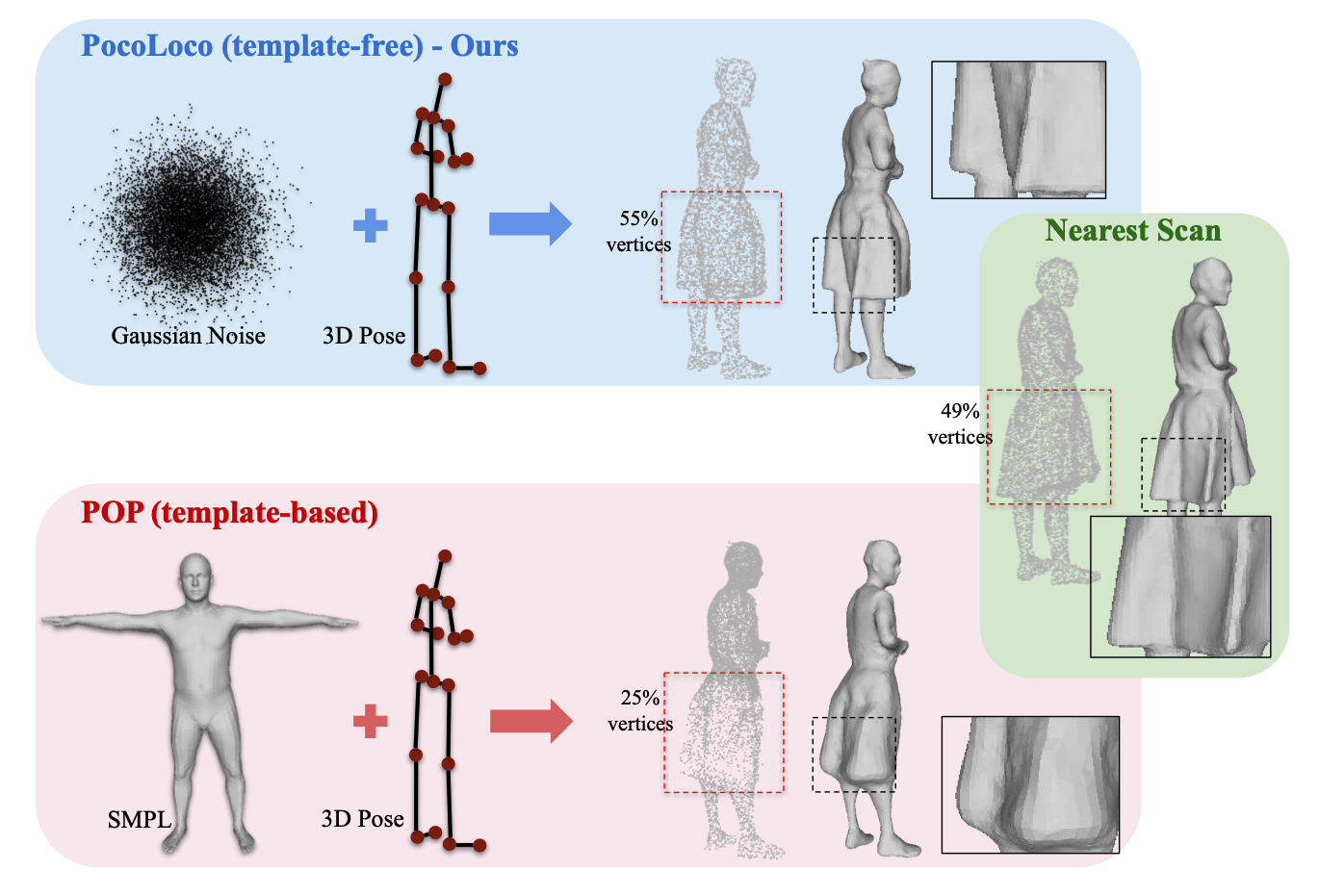
AbstractModeling a human avatar that can plausibly deform to articulations is an active area of research. We present PocoLoco – the first template-free, point-based, pose conditioned generative model for 3D humans in loose clothing. We motivate our work by noting that most methods require a parametric model of the human body to ground pose-dependent deformations. Consequently, they are restricted to modeling clothing that is topologically similar to the naked body and do not extend well to loose clothing. The few methods that attempt to model loose clothing typically require either canonicalization or a UV-parameterization and need to address the challenging problem of explicitly estimating correspondences for the deforming clothes. In this work, we formulate avatar clothing deformation as a conditional point-cloud generation task within the denoising diffusion framework. Crucially, our framework operates directly on unordered point clouds, eliminating the need for a parametric model or a clothing template. This also enables a variety of practical applications, such as point-cloud completion and pose-based editing – important features for virtual human animation. As current datasets for human avatars in loose clothing are far too small for training diffusion models, we release a dataset of two subjects performing various poses in loose clothing with a total of 75K point clouds. By contributing towards tackling the challenging task of effectively modeling loose clothing and expanding the available data for training these models, we aim to set the stage for further innovation in digital humans.
|
2024
 |
TriHuman: A Real-time and Controllable Tri-plane Representation for Detailed Human Geometry and Appearance Synthesis
Heming Zhu
Fangneng Zhan
Christian Theobalt
Marc Habermann
ToG 2024 (presented at Siggraph Asia 2024)
Abstract Creating controllable, photorealistic, and geometrically detailed digital doubles of real humans solely from video data is a key challenge in Computer Graphics and Vision, especially when real-time performance is required. Recent methods attach a neural radiance field (NeRF) to an articulated structure, e.g., a body model or a skeleton, to map points into a pose canonical space while conditioning the NeRF on the skeletal pose. These approaches typically parameterize the neural field with a multi-layer perceptron (MLP) leading to a slow runtime. To address this drawback, we propose TriHuman a novel human-tailored, deformable, and efficient tri-plane representation, which achieves real-time performance, state-of-the-art pose-controllable geometry synthesis as well as photorealistic rendering quality. At the core, we non-rigidly warp global ray samples into our undeformed tri-plane texture space, which effectively addresses the problem of global points being mapped to the same tri-plane locations. We then show how such a tri-plane feature representation can be conditioned on the skeletal motion to account for dynamic appearance and geometry changes. Our results demonstrate a clear step towards higher quality in terms of geometry and appearance modeling of humans and runtime performance.
|
EgoAvatar: Egocentric View-Driven and Photorealistic Full-body Avatars
Jianchun Chen
Jian Wang
Yinda Zhang
Rohit Pandey
Thabo Beeler
Marc Habermann
Christian Theobalt
Siggraph Asia 2024
Abstract
Immersive VR telepresence ideally means being able to interact and communicate with digital avatars that are indistinguishable from and precisely reflect the behaviour of their real counterparts. The core technical challenge is two fold: Creating a digital double that faithfully reflects the real human and tracking the real human solely from egocentric sensing devices that are lightweight and have a low energy consumption, e.g. a single RGB camera. Up to date, no unified solution to this problem exists as recent works solely focus on egocentric motion capture, only model the head, or build avatars from multi-view captures. In this work, we, for the first time in literature, propose a person-specific egocentric telepresence approach, which jointly models the photoreal digital avatar while also driving it from a single egocentric video. We first present a character model that is animatible, i.e. can be solely driven by skeletal motion, while being capable of modeling geometry and appearance. Then, we introduce a personalized egocentric motion capture component, which recovers full-body motion from an egocentric video. Finally, we apply the recovered pose to our character model and perform a test-time mesh refinement such that the geometry faithfully projects onto the egocentric view. To validate our design choices, we propose a new and challenging benchmark, which provides paired egocentric and dense multi-view videos of real humans performing various motions. Our experiments demonstrate a clear step towards egocentric and photoreal telepresence as our method outperforms baselines as well as competing methods.
|
‚
 |
GaussianHeads: End-to-End Learning of Drivable Gaussian Head Avatars from Coarse-to-fine Representations
Kartik Teotia
Hyeongwoo Kim
Pablo Garrido
Marc Habermann
Mohamed Elgharib
Christian Theobalt
Siggraph Asia 2024
Abstract
Real-time rendering of human head avatars is a cornerstone of many computer graphics applications, such as augmented reality, video games, and films, to name a few. Recent approaches address this challenge with computationally efficient geometry primitives in a carefully calibrated multi-view setup. Albeit producing photorealistic head renderings, it often fails to represent complex motion changes such as the mouth interior and strongly varying head poses. We propose a new method to generate highly dynamic and deformable human head avatars from multi-view imagery in real-time. At the core of our method is a hierarchical representation of head models that allows to capture the complex dynamics of facial expressions and head movements. First, with rich facial features extracted from raw input frames, we learn to deform the coarse facial geometry of the template mesh. We then initialize 3D Gaussians on the deformed surface and refine their positions in a fine step. We train this coarse-to-fine facial avatar model along with the head pose as a learnable parameter in an end-to-end framework. This enables not only controllable facial animation via video inputs, but also high-fidelity novel view synthesis of challenging facial expressions, such as tongue deformations and fine-grained teeth structure under large motion changes. Moreover, it encourages the learned head avatar to generalize towards new facial expressions and head poses at inference time. We demonstrate the performance of our method with comparisons against the related methods on different datasets, spanning challenging facial expression sequences across multiple identities. We also show the potential application of our approach by demonstrating a cross-identity facial performance transfer application.
|
 |
Manifold Sampling for Differentiable Uncertainty in Radiance Fields
Linjie Lyu
Ayush Tewari
Marc Habermann
Shunsuke Saito
Michael Zollhoefer Thomas Leimkühler Christian Theobalt Siggraph Asia 2024 Abstract
Radiance fields are powerful and, hence, popular models for representing the appearance of complex scenes. Yet, constructing them based on image observations gives rise to ambiguities and uncertainties. We propose a versatile approach for learning Gaussian radiance fields with explicit and fine-grained uncertainty estimates that impose only little additional cost compared to uncertainty-agnostic training. Our key observation is that uncertainties can be modeled as a low-dimensional manifold in the space of radiance field parameters that is highly amenable to Monte Carlo sampling. Importantly, our uncertainties are differentiable and, thus, allow for gradient-based optimization of subsequent captures that optimally reduce ambiguities. We demonstrate state-of-the-art performance on next-best-view planning tasks, including high-dimensional illumination planning for optimal radiance field relighting quality.
|
 |
NeuralClothSim: Neural Deformation Fields Meet the Kirchhoff-Love Thin Shell Theory
Navami Kairanda
Marc Habermann
Christian Theobalt
Vladislav Golyanik
Neurips 2024
AbstractDespite existing 3D cloth simulators producing realistic results, they predominantly operate on discrete surface representations (e.g. points and meshes) with a fixed spatial resolution, which often leads to large memory consumption and resolution-dependent simulations. Moreover, back-propagating gradients through the existing solvers is difficult, and they hence cannot be easily integrated into modern neural architectures. In response, this paper re-thinks physically plausible cloth simulation: We propose NeuralClothSim, i.e., a new quasistatic cloth simulator using thin shells, in which surface deformation is encoded in neural network weights in the form of a neural field. Our memory-efficient solver operates on a new continuous coordinate-based surface representation called neural deformation fields (NDFs); it supervises NDF equilibria with the laws of the non-linear Kirchhoff-Love shell theory with a non-linear anisotropic material model. NDFs are adaptive: They 1) allocate their capacity to the deformation details and 2) allow surface state queries at arbitrary spatial resolutions without re-training. We show how to train NeuralClothSim while imposing hard boundary conditions and demonstrate multiple applications, such as material interpolation and simulation editing. The experimental results highlight the effectiveness of our continuous neural formulation.
|
 |
MetaCap: Meta-learning Priors from Multi-View Imagery for Sparse-view Human Performance Capture and Rendering
Guoxing Sun
Rishabh Dabral
Pascal Fua
Christian Theobalt
Marc Habermann
ECCV 2024
Abstract
Faithful human performance capture and free-view render- ing from sparse RGB observations is a long-standing problem in Vision and Graphics. The main challenges are the lack of observations and the inherent ambiguities of the setting, e.g. occlusions and depth ambiguity. As a result, radiance fields, which have shown great promise in capturing high-frequency appearance and geometry details in dense setups, perform poorly when naïvely supervising them on sparse camera views, as the field simply overfits to the sparse-view inputs. To address this, we propose MetaCap, a method for efficient and high-quality geometry recovery and novel view synthesis given very sparse or even a single view of the human. Our key idea is to meta-learn the radiance field weights solely from potentially sparse multi-view videos, which can serve as a prior when fine-tuning them on sparse imagery depicting the human. This prior provides a good network weight initialization, thereby effectively addressing ambiguities in sparse-view capture. Due to the articulated structure of the human body and motion-induced surface deformations, learning such a prior is non-trivial. Therefore, we propose to meta-learn the field weights in a pose-canonicalized space, which reduces the spatial feature range and makes feature learning more effective. Consequently, one can fine-tune our field parameters to quickly generalize to unseen poses, novel illumination conditions as well as novel and sparse (even monocular) camera views. For evaluating our method under different scenarios, we collect a new dataset, WildDynaCap, which contains subjects captured in, both, a dense camera dome and in-the-wild sparse camera rigs, and demonstrate superior results compared to recent state-of-the-art methods on both public and WildDynaCap dataset.
|
 |
Relightable Neural Actor with Intrinsic Decomposition and Pose Control
Diogo Luvizon
Vladislav Golyanik
Adam Kortylewski
Marc Habermann
Christian Theobalt
ECCV 2024
AbstractCreating a controllable and relightable digital avatar from multi-view video with fixed illumination is a very challenging problem since humans are highly articulated, creating pose-dependent appearance effects, and skin as well as clothing require space-varying BRDF modeling. Existing works on creating animatible avatars either to not focus on relighting at all, require controlled illumination setups, or try to recover a relightable avatar from very low cost setups, i.e. a single RGB video, at the cost of severely limited result quality, e.g. shadows not even being modeled. To address this, we propose Relightable Neural Actor, a new video-based method for learning a pose-driven neural human model that can be relighted, allows appearance editing, and models pose-dependent effects such as wrinkles and self-shadows. Importantly, for training, our method solely requires a multi-view recording of the human under a known, but static lighting condition. To tackle this challenging problem, we leverage an implicit geometry representation of the actor with a drivable density field that models pose-dependent deformations and derive a dynamic mapping between 3D and UV spaces, where normal, visibility, and materials are effectively encoded. To evaluate our approach in real-world scenarios, we collect a new dataset with four identities recorded under different light conditions, indoors and outdoors, providing the first benchmark of its kind for human relighting, and demonstrating state-of-the-art relighting results for novel human poses.
|
 |
Surf-D: High-Quality Surface Generation for Arbitrary Topologies using Diffusion Models
Zhengming Yu
Zhiyang Dou
Xiaoxiao Long
Cheng Lin
Zekun Li
Yuan Liu
Norman Mueller
Taku Komura
Marc Habermann
Christian Theobalt
Xin Li
Wenping Wang
ECCV 2024
AbstractWe present Surf-D, a novel method for generating high-quality 3D shapes as Surfaces with arbitrary topologies using Diffusion models. Specifically, we adopt Unsigned Distance Field (UDF) as the surface representation, as it excels in handling arbitrary topologies, enabling the generation of complex shapes. While the prior methods explored shape generation with different representations, they suffer from limited topologies and geometry details. Moreover, it's non-trivial to directly extend prior diffusion models to UDF because they lack spatial continuity due to the discrete volume structure. However, UDF requires accurate gradients for mesh extraction and learning. To tackle the issues, we first leverage a point-based auto-encoder to learn a compact latent space, which supports gradient querying for any input point through differentiation to effectively capture intricate geometry at a high resolution. Since the learning difficulty for various shapes can differ, a curriculum learning strategy is employed to efficiently embed various surfaces, enhancing the whole embedding process. With pretrained shape latent space, we employ a latent diffusion model to acquire the distribution of various shapes. Our approach demonstrates superior performance in shape generation across multiple modalities and conducts extensive experiments in unconditional generation, category conditional generation, 3D reconstruction from images, and text-to-shape tasks.
|
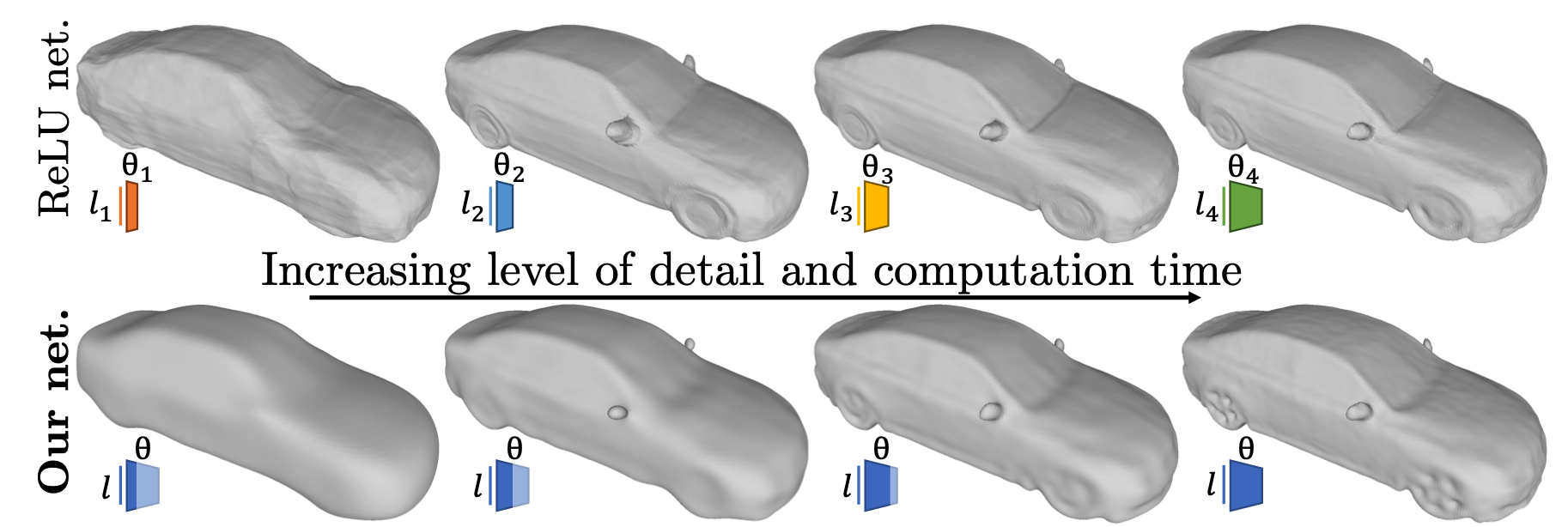 |
A Latent Implicit 3D Shape Model for Multiple Levels of Detail
Benoit Guillard
Marc Habermann
Christian Theobalt
Pascal Fua
GCPR 2024
Abstract
Implicit neural representations map a shape-specific latent code and a 3D coordinate to its corresponding signed distance (SDF) value. However, this approach only offers a single level of detail. Emulating low levels of detail can be achieved with shallow networks, but the generated shapes are typically not smooth. Alternatively, some network designs offer multiple levels of detail, but are limited to overfitting a single object. To address this, we propose a new shape modeling approach, which enables multiple levels of detail and guarantees a smooth surface at each level. At the core, we introduce a novel latent conditioning for a multiscale and bandwith-limited neural architecture. This results in a deep parameterization of multiple shapes, where early layers quickly output approximated SDF values. This allows to balance speed and accuracy within a single network and enhance the efficiency of implicit scene rendering. We demonstrate that by limiting the bandwidth of the network, we can maintain smooth surfaces across all levels of detail. At finer levels, reconstruction quality is on par with the state of the art models, which are limited to a single level of detail.
|
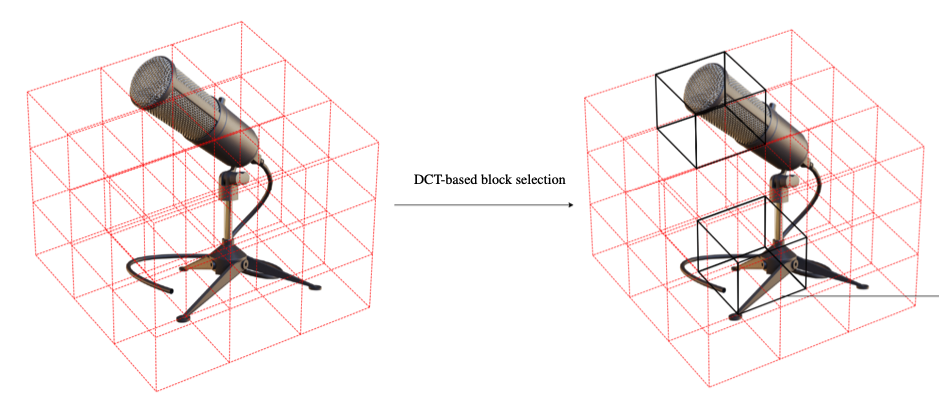 |
Adaptive Grids for Neural Scene Representation
Barbod Pajoum
Gereon Fox
Mohamed Elgharib
Marc Habermann
Christian Theobalt
VMV 2024
Abstract
We introduce a novel versatile approach to enhance the quality of grid-based neural scene representations. Grid-based scene representations model a scene by storing density and color features at discrete 3D points, which offers faster training and rendering than purely implicit methods such as NeRF. However, they require high-resolution grids to achieve high-quality outputs, leading to a significant increase in memory usage. Common standard grids with uniform voxel sizes do not account for the varying complexity of different regions within a scene. This is particularly evident when a highly detailed region or object is present, while the rest of the scene is less significant or simply empty. To address this we introduce a novel approach based on frequency domain transformations for finding the key regions in the scene and then utilize a 2-level hierarchy of grids to allocate more resources to more detailed regions. We also created a more efficient version of this concept, that adapts to a compact grid representation, namely TensoRF, which also works for very few training samples.
|
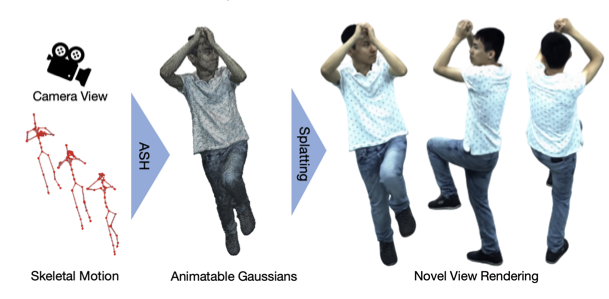 |
ASH: Animatable Gaussian Splats for Efficient and Photoreal Human Rendering
Haokai Pang
Heming Zhu
Adam Kortylewski
Christian Theobalt
Marc Habermann
CVPR 2024
Abstract Real-time rendering of photorealistic and controllable human avatars stands as a cornerstone in Computer Vision and Graphics. While recent advances in neural implicit rendering have unlocked unprecedented photorealism for digital avatars, real-time performance has mostly been demonstrated for static scenes only. To address this, we propose ASH, an Animatable Gaussian Splatting approach for photorealistic rendering of dynamic Humans in real time. We parameterize the clothed human as animatable 3D Gaussians, which can be efficiently splatted into image space to generate the final rendering. However, naively learning the Gaussian parameters in 3D space poses a severe challenge in terms of compute. Instead, we attach the Gaussians onto a deformable character model, and learn their parameters in 2D texture space, which allows leveraging efficient 2D convolutional architectures that easily scale with the required number of Gaussians. We benchmark ASH with competing methods on pose-controllable avatars, demonstrating that our method outperforms existing real-time methods by a large margin and shows comparable or even better results than offline methods.
|
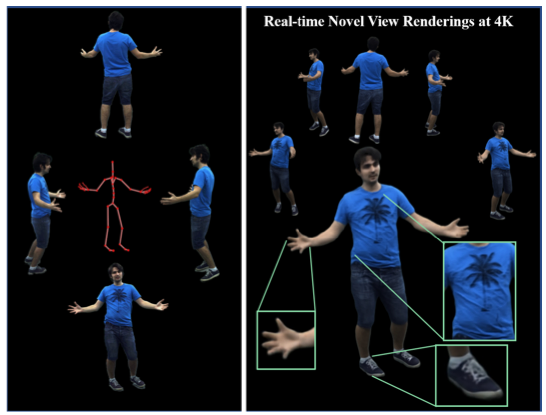 |
Holoported Characters: Real-time Free-viewpoint Rendering of Humans from Sparse RGB Cameras Rendering
Ashwath Shetty
Marc Habermann
Guoxing Sun
Diogo Luvizon
Vladislav Golyanik
Christian Theobalt
CVPR 2024
Abstract We present the first approach to render highly realistic free-viewpoint videos of a human actor in general apparel, from sparse multi-view recording to display, in real-time at an unprecedented 4K resolution. At inference, our method only requires four camera views of the moving actor and the respective 3D skeletal pose. It handles actors in wide clothing, and reproduces even fine-scale dynamic detail, e.g. clothing wrinkles, face expressions, and hand gestures. At training time, our learning-based approach expects dense multi-view video and a rigged static surface scan of the actor. Our method comprises three main stages. Stage 1 is a skeleton-driven neural approach for high-quality capture of the detailed dynamic mesh geometry. Stage 2 is a novel solution to create a view-dependent texture using four test-time camera views as input. Finally, stage 3 comprises a new image-based refinement network rendering the final 4K image given the output from the previous stages. Our approach establishes a new benchmark for real-time rendering resolution and quality using sparse input camera views, unlocking possibilities for immersive telepresence.
|
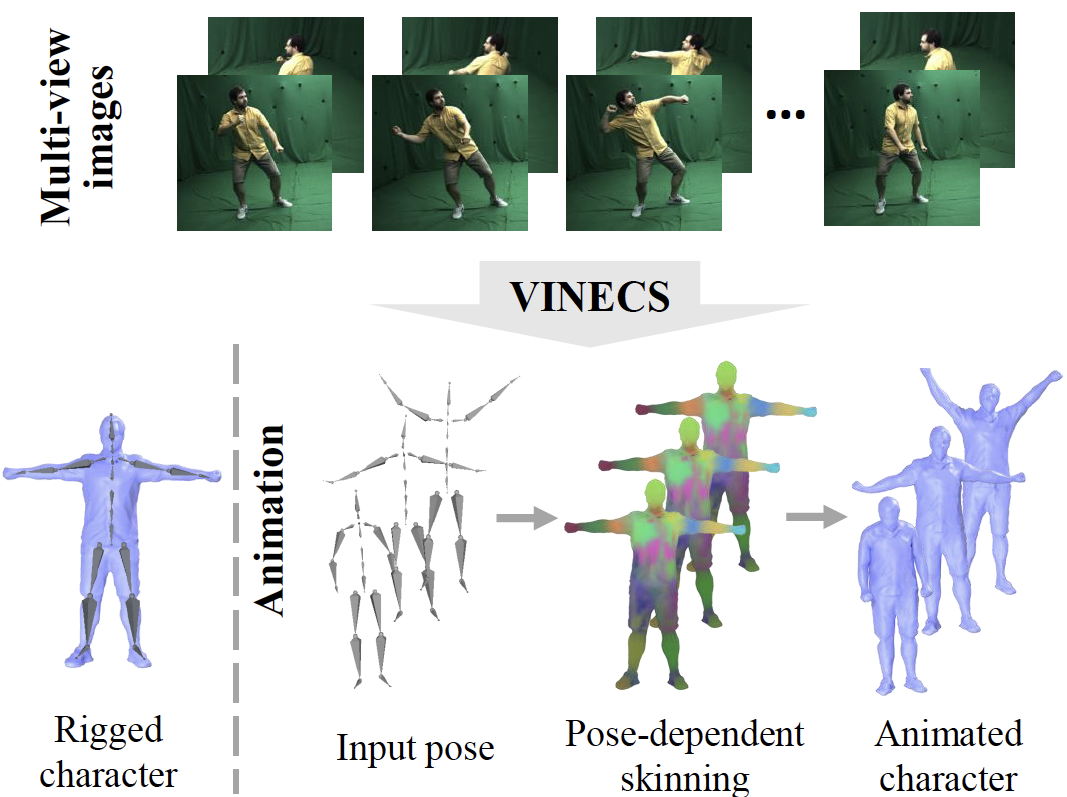 |
VINECS: Video-based Neural Character Skinning
Zhouyingcheng Liao
Vladislav Golyanik
Marc Habermann
Christian Theobalt
CVPR 2024
Abstract Rigging and skinning clothed human avatars is a challenging task and traditionally requires a lot of manual work and expertise. Recent methods addressing it either generalize across different characters or focus on capturing the dynamics of a single character observed under different pose configurations. However, the former methods typically predict solely static skinning weights, which perform poorly for highly articulated poses, and the latter ones either require dense 3D character scans in different poses or cannot generate an explicit mesh with vertex correspondence over time. To address these challenges, we propose a fully automated approach for creating a fully rigged character with pose-dependent skinning weights, which can be solely learned from multi-view video. Therefore, we first acquire a rigged template, which is then statically skinned. Next, a coordinate-based MLP learns a skinning weights field parameterized over the position in a canonical pose space and the respective pose. Moreover, we introduce our pose- and view-dependent appearance field allowing us to differentiably render and supervise the posed mesh using multi-view imagery. We show that our approach outperforms state-of-the-art while not relying on dense 4D scans.
|
 |
Wonder3D: Single Image to 3D using Cross-Domain Diffusion
Xiaoxiao Long
Yuan-Chen Guo
Cheng Lin
Yuan Liu
Zhiyang Dou
Lingjie Liu
Yuexin Ma
Song-Hai Zhang
Marc Habermann
Christian Theobalt
Wenping Wang
CVPR 2024
Poster Highlight (11.9% of accepted papers)
AbstractIn this work, we introduce Wonder3D, a novel method for efficiently generating high-fidelity textured meshes from single-view images. Recent methods based on Score Dis- tillation Sampling (SDS) have shown the potential to re- cover 3D geometry from 2D diffusion priors, but they typ- ically suffer from time-consuming per-shape optimization and inconsistent geometry. In contrast, certain works di- rectly produce 3D information via fast network inferences, but their results are often of low quality and lack geomet- ric details. To holistically improve the quality, consistency, and efficiency of single-view reconstruction tasks, we pro- pose a cross-domain diffusion model that generates multi- view normal maps and the corresponding color images. To ensure the consistency of generation, we employ a multi- view cross-domain attention mechanism that facilitates in- formation exchange across views and modalities. Lastly, we introduce a geometry-aware normal fusion algorithm that extracts high-quality surfaces from the multi-view 2D rep- resentations. Our extensive evaluations demonstrate that our method achieves high-quality reconstruction results, ro- bust generalization, and good efficiency compared to prior works.
|
 |
ConvoFusion: Multi-Modal Conversational Diffusion
for Co-Speech Gesture Synthesis
Muhammad Hamza Mughal
Rishabh Dabral
Ikhsanul Habibie
Lucia Donatelli
Marc Habermann
Christian Theobalt
CVPR 2024
AbstractGestures play a key role in human communication. Recent methods for co-speech gesture generation, while managing to generate beat-aligned motions, struggle generating gestures that are semantically aligned with the utterance. Compared to beat gestures that align naturally to the audio signal, generating semantically coherent gestures require modeling the complex interactions between the words, their meaning and the human motion. Therefore, we present ConvoFusion, a diffusion-based approach for multi-modal gesture synthesis, which can not only generate gestures based on multi-modal speech inputs, but can also facilitate controllability in gesture synthesis. Our method proposes two guidance objectives that allow the users to modulate the impact of different conditioning modalities (e.g. audio vs text) as well as to choose certain words to be emphasized during gesturing. Our method is versatile in that it can be trained either for generating monologue gestures or even the conversational gestures. To further advance the research on multi-party interactive gestures, the DND Group Gesture dataset is released, which contains 6 hours of gesture data showing 5 people interacting with one another. We compare our method with several recent works and demonstrate effectiveness of our method on a variety of tasks.
|
 |
ROAM: Robust and Object-aware Motion Generation using Neural Pose Descriptors
Wanyue Zhang
Rishabh Dabral
Thomas Leimkühler
Vladislav Golyanik
Marc Habermann
Christian Theobalt
3DV 2024
AbstractExisting automatic approaches for 3D virtual character motion synthesis supporting scene interactions do not generalise well to new objects outside training distributions, even when trained on extensive motion capture datasets with diverse objects and annotated interactions. This paper addresses this limitation and shows that robustness and generalisation to novel scene objects in 3D object-aware character synthesis can be achieved by training a motion model with as few as one reference object. We leverage an implicit feature representation trained on object-only datasets, which encodes an SE(3)-equivariant descriptor field around the object. Given an unseen object and a reference pose-object pair, we optimise for the object-aware pose that is closest in the feature space to the reference pose.Finally, we use l-NSM, i.e. our motion generation model that is trained to seamlessly transition from locomotion to object interaction with the proposed bidirectional pose blending scheme. Through comprehensive numerical comparisons to state-of-the-art methods and in a user study, we demonstrate substantial improvements in 3D virtual character motion and interaction quality and robustness to scenarios with unseen objects.
|
2023
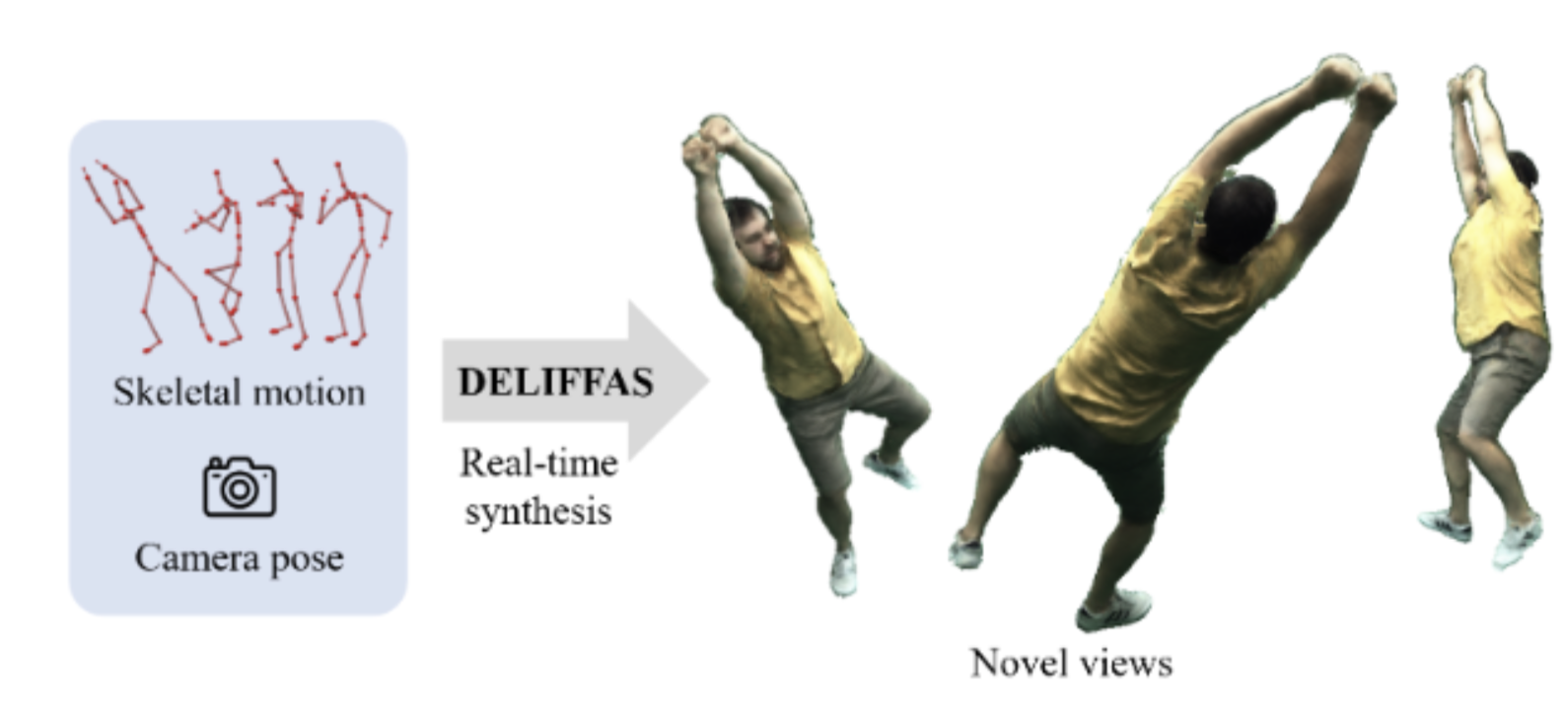 |
DELIFFAS: Deformable Light Fields for Fast Avatar Synthesis
Youngjoong Kwon
Lingjie Liu
Henry Fuchs
Marc Habermann
Christian Theobalt
Neurips 2023
Abstract
Generating controllable and photorealistic digital human avatars is a long-standing and important problem in Vision and Graphics. Recent methods have shown great progress in terms of either photorealism or inference speed while the combination of the two desired properties still remains unsolved. To this end, we propose a novel method, called DELIFFAS, which parameterizes the appearance of the human as a surface light field that is attached to a controllable and deforming human mesh model. At the core, we represent the light field around the human with a deformable two-surface parameterization, which enables fast and accurate inference of the human appearance. This allows perceptual supervision on the full image compared to previous approaches that could only supervise individual pixels or small patches due to their slow runtime. Our carefully designed human representation and supervision strategy leads to state-of-the-art synthesis results and inference time.
|
 |
Diffusion Posterior Illumination for Ambiguity-aware Inverse Rendering
Linjie Lyu
Ayush Tewari
Marc Habermann
Shunsuke Saito
Michael Zollhoefer Thomas Leimkühler Christian Theobalt Siggraph Asia 2023 Abstract
Inverse rendering, the process of inferring scene properties from images, is a challenging inverse problem. The task is ill-posed, as many different scene configurations can give rise to the same image. Most existing solutions incorporate priors into the inverse-rendering pipeline to encourage plausible solutions, but they do not consider the inherent ambiguities and the multi-modal distribution of possible decompositions. In this work, we propose a novel scheme that integrates a denoising diffusion probabilistic model pre-trained on natural illumination maps into an optimization framework involving a differentiable path tracer. The proposed method allows sampling from combinations of illumination and spatially-varying surface materials that are, both, natural and explain the image observations. We further conduct an extensive comparative study of different priors on illumi- nation used in previous work on inverse rendering. Our method excels in recovering materials and producing highly realistic and diverse environment map samples that faithfully explain the illumination of the input images.
|
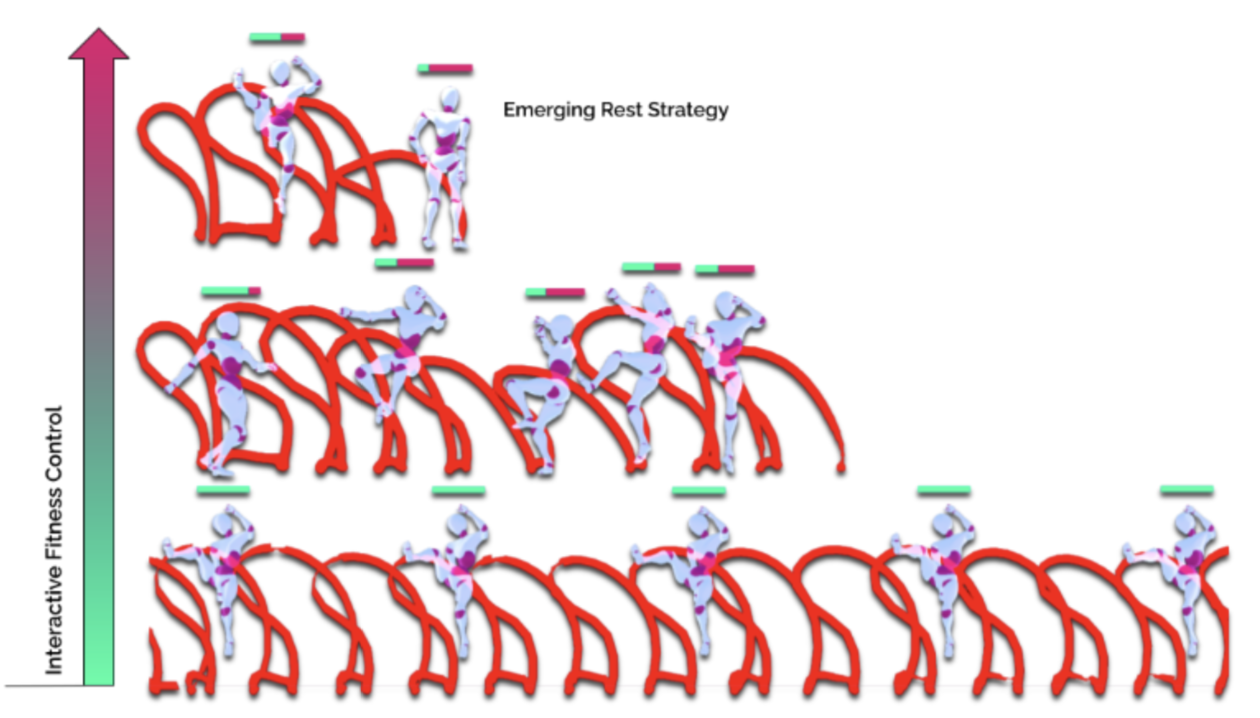 |
Discovering Fatigued Movements for Virtual Character Animation
Noshaba Cheema
Rui Xu
Nam Hee Kim
Perttu Hämäläinen
Vladislav Golyanik
Marc Habermann
Christian Theobalt
Philipp Slusallek
Siggraph Asia 2023
Abstract
Virtual character animation and movement synthesis have advanced rapidly during recent years, especially through a combination of extensive motion capture datasets and machine learning. A remaining challenge is interactively simulating characters that fatigue when performing extended motions, which is indispensable for the realism of generated animations. However, capturing such movements is problematic, as performing movements like backflips with fatigued variations up to exhaustion raises capture cost and risk of injury. Surprisingly, little research has been done on faithful fatigue modeling. To address this, we propose a deep reinforcement learning-based approach, which—for the first time in literature—generates control policies for full-body physically simulated agents aware of cumulative fatigue. For this, we first leverage Generative Adversarial Imitation Learning (GAIL) to learn an expert policy for the skill; Second, we learn a fatigue policy by limiting the generated constant torque bounds based on endurance time to non-linear, state- and time-dependent limits in the joint-actuation space using a Three-Compartment Controller (3CC) model. Our results demonstrate that agents can adapt to different fatigue and rest rates interactively, and discover realistic recovery strategies without the need for any captured data of fatigued movements.
|
 |
LiveHand: Real-time and Photorealistic Neural Hand Rendering
Akshay Mundra
Mallikarjun B R
Jiayi Wang
Marc Habermann
Christian Theobalt Mohamed Elgharib ICCV 2023 AbstractThe human hand is the main medium through which we interact with our surroundings. Hence, its digitization is of uttermost importance, with direct applications in VR/AR, gaming, and media production amongst other areas. While there are several works modeling the geometry of hands, little attention has been paid to capturing photo-realistic appearance. Moreover, for applications in extended reality and gaming, real-time rendering is critical. We present the first neural- implicit approach to photo-realistically render hands in real-time. This is a challenging problem as hands are textured and undergo strong articulations with pose-dependent effects. However, we show that this aim is achievable through our carefully designed method. This includes training on a low- resolution rendering of a neural radiance field, together with a 3D-consistent super-resolution module and mesh-guided sampling and space canonicaliza- tion. We demonstrate a novel application of perceptual loss on the image space, which is critical for learning details accurately. We also show a live demo where we photo-realistically render the human hand in real-time for the first time, while also modeling pose- and view-dependent appearance effects. We ablate all our design choices and show that they optimize for rendering speed and quality.
|
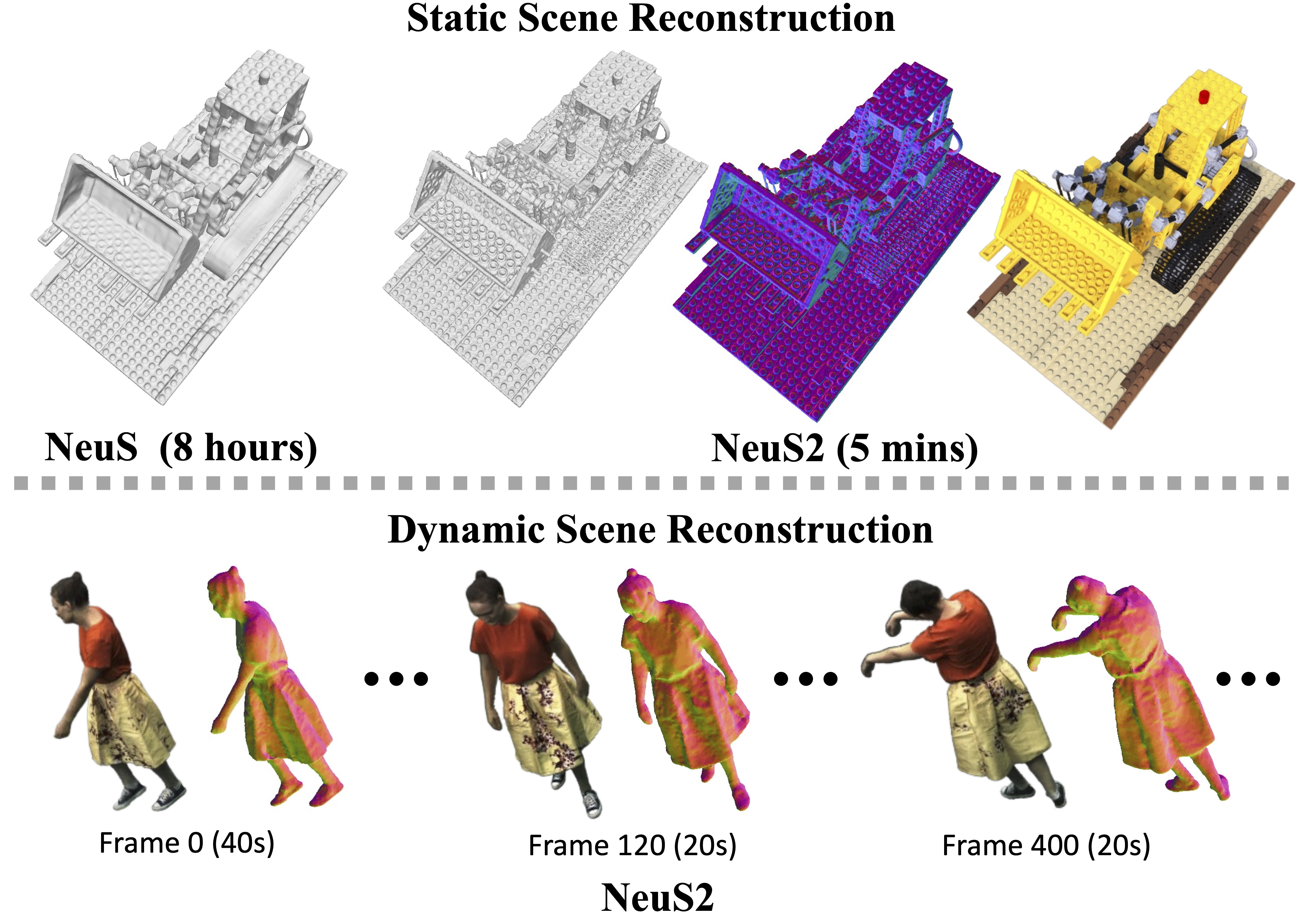 |
NeuS2: Fast Learning of Neural Implicit Surfaces for Multi-view Reconstruction
Yiming Wang
Qin Han
Marc Habermann
Kostas Daniilidis
Christian Theobalt Lingjie Liu ICCV 2023 AbstractRecent methods for neural surface representation and rendering, for example NeuS, have demonstrated remarkably high-quality reconstruction of static scenes. However, the training of NeuS takes an extremely long time (8~hours), which makes it almost impossible to apply them to dynamic scenes with thousands of frames. We propose a fast neural surface reconstruction approach, called NeuS2, which achieves two orders of magnitude improvement in terms of acceleration without compromising reconstruction quality. To accelerate the training process, we integrate multi-resolution hash encodings into a neural surface representation and implement our whole algorithm in CUDA. We also present a lightweight calculation of second-order derivatives tailored to our networks (i.e., ReLU-based MLPs), which achieves a factor two speed up. To further stabilize training, a progressive learning strategy is proposed to optimize multi-resolution hash encodings from coarse to fine. In addition, we extend our method for reconstructing dynamic scenes with an incremental training strategy. Our experiments on various datasets demonstrate that NeuS2 significantly outperforms the state-of-the-arts in both surface reconstruction accuracy and training speed.
|
 |
HDHumans: A Hybrid Approach for High-fidelity Digital Humans
Marc Habermann
Lingjie Liu
Weipeng Xu
Gerard Pons-Moll
Michael Zollhoefer Christian Theobalt SCA 2023 Best Paper Honorable Mention AbstractPhoto-real digital human avatars are of enormous importance in graphics, as they enable immersive communication over the globe, improve gaming and entertainment experiences, and can be particularly beneficial for AR and VR settings. However, current avatar generation approaches either fall short in high-fidelity novel view synthesis, generalization to novel motions, reproduction of loose clothing, or they cannot render characters at the high resolution offered by modern displays. To this end, we propose HDHumans, which is the first method for HD human character synthesis that jointly produces an accurate and temporally coherent 3D deforming surface and highly photo-realistic images of arbitrary novel views and of motions not seen at training time. At the technical core, our method tightly integrates a classical deforming character template with neural radiance fields (NeRF). Our method is carefully designed to achieve a synergy between classical surface deformation and NeRF. First, the template guides the NeRF, which allows synthesizing novel views of a highly dynamic and articulated char- acter and even enables the synthesis of novel motions. Second, we also leverage the dense pointclouds resulting from NeRF to further improve the deforming surface via 3D-to-3D supervision. We outperform the state of the art quantitatively and qualitatively in terms of synthesis quality and resolution, as well as the quality of 3D surface reconstruction.
|
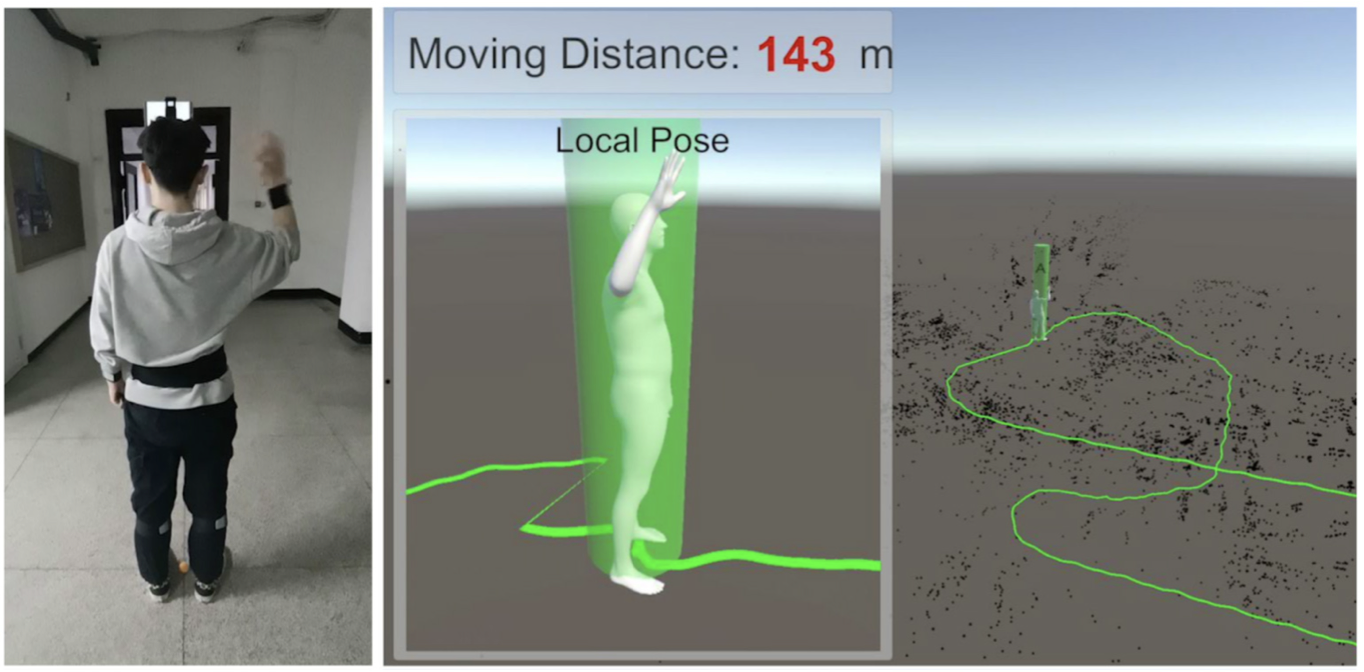 |
EgoLocate: Real-time Motion Capture, Localization, and Mapping with Sparse Body-mounted Sensors
Xinyu Yi
Yuxiao Zhou
Marc Habermann
Vladislav Golyanik
Shaohua Pan
Christian Theobalt Feng Xu SIGGRAPH 2023 AbstractHuman and environment sensing are two important topics in Computer Vision and Graphics. Human motion is often captured by inertial sensors (left), while the environment is mostly reconstructed using cameras (right). We integrate the two techniques together in EgoLocate (middle), a system that simultaneously performs human motion capture (mocap), localization, and mapping in real time from sparse body-mounted sensors, including 6 inertial measurement units (IMUs) and a monocular phone camera. On one hand, inertial mocap suffers from large translation drift due to the lack of the global positioning signal. EgoLocate leverages image-based simultaneous localization and mapping (SLAM) techniques to locate the human in the reconstructed scene. On the other hand, SLAM often fails when the visual feature is poor. EgoLocate involves inertial mocap to provide a strong prior for the camera motion. Experiments show that localization, a key challenge for both two fields, is largely improved by our technique, compared with the state of the art of the two fields.
|
 |
Unbiased 4D: Monocular 4D Reconstruction with a Neural Deformation Model
Erik C.M. Johnson
Marc Habermann
Soshi Shimada
Vladislav Golyanik
Christian Theobalt
CVPR Workshop 2023
AbstractCapturing general deforming scenes is crucial for many applications in computer graphics and vision, and it is especially challenging when only a monocular RGB video of the scene is available. Competing methods assume dense point tracks over the input views, 3D templates, large-scale training datasets, or only capture small-scale deformations. In stark contrast to those, our method makes none of these assumptions while significantly outperforming the previous state of the art in challenging scenarios. Moreover, our technique includes two new—in the context of non-rigid 3D reconstruction—components, i.e., 1) A coordinate-based and implicit neural representation for non-rigid scenes, which enables an unbiased reconstruction of dynamic scenes, and 2) A novel dynamic scene flow loss, which enables the reconstruction of larger deformations. Results on our new dataset, which will be made publicly available, demonstrate the clear improvement over the state of the art in terms of surface reconstruction accuracy and robustness to large deformations.
|
State of the Art in Dense Monocular Non-Rigid 3D Reconstruction
Edith Tretschk
Navami Kairanda
Mallikarjun B R
Rishabh Dabral
Adam Kortylewski
Bernhard Egger
Marc Habermann
Pascal Fua
Christian Theobalt
Vladislav Golyanik
Eurographics 2023 (STAR Report)
Abstract3D reconstruction of deformable (or non-rigid) scenes from a set of monocular 2D image observations is a long-standing and actively researched area of computer vision and graphics. It is an ill-posed inverse problem, since—without additional prior assumptions—it permits infinitely many solutions leading to accurate projection to the input 2D images. Non-rigid reconstruction is a foundational building block for downstream applications like robotics, AR/VR, or visual content creation. The key advantage of using monocular cameras is their omnipresence and availability to the end users as well as their ease of use compared to more sophisticated camera set-ups such as stereo or multi-view systems. This survey focuses on state-of-the-art methods for dense non-rigid 3D reconstruction of various deformable objects and composite scenes from monocular videos or sets of monocular views. It reviews the fundamentals of 3D reconstruction and deformation modeling from 2D image observations. We then start from general methods—that handle arbitrary scenes and make only a few prior assumptions—and proceed towards techniques making stronger assumptions about the observed objects and types of deformations (e.g. human faces, bodies, hands, and animals). A significant part of this STAR is also devoted to classification and a high-level comparison of the methods, as well as an overview of the datasets for training and evaluation of the discussed techniques. We conclude by discussing open challenges in the field and the social aspects associated with the usage of the reviewed methods.
|
 |
Scene-Aware 3D Multi-Human Motion Capture from a Single Camera
Diogo Luvizon
Marc Habermann
Vladislav Golyanik
Adam Kortylewski
Christian Theobalt
Eurographics 2023
AbstractIn this work, we consider the problem of estimating the 3D position of multiple humans in a scene as well as their body shape and articulation from a single RGB video recorded with a static camera. In contrast to expensive marker-based or multi-view systems, our lightweight setup is ideal for private users as it enables an affordable 3D motion capture that is easy to install and does not require expert knowledge. To deal with this challenging setting, we leverage recent advances in computer vision using large-scale pre-trained models for a variety of modalities, including 2D body joints, joint angles, normalized disparity maps, and human segmentation masks. Thus, we introduce the first non-linear optimization-based approach that jointly solves for the absolute 3D position of each human, their articulated pose, their individual shapes as well as the scale of the scene. In particular, we estimate the scene depth and person unique scale from normalized disparity predictions using the 2D body joints and joint angles. Given the per-frame scene depth, we reconstruct a point-cloud of the static scene in 3D space. Finally, given the per-frame 3D estimates of the humans and scene point-cloud, we perform a space-time coherent optimization over the video to ensure temporal, spatial and physical plausibility. We evaluate our method on established multi-person 3D human pose benchmarks where we consistently outperform previous methods and we qualitatively demonstrate that our method is robust to in-the-wild conditions including challenging scenes with people of different sizes.
|
2022
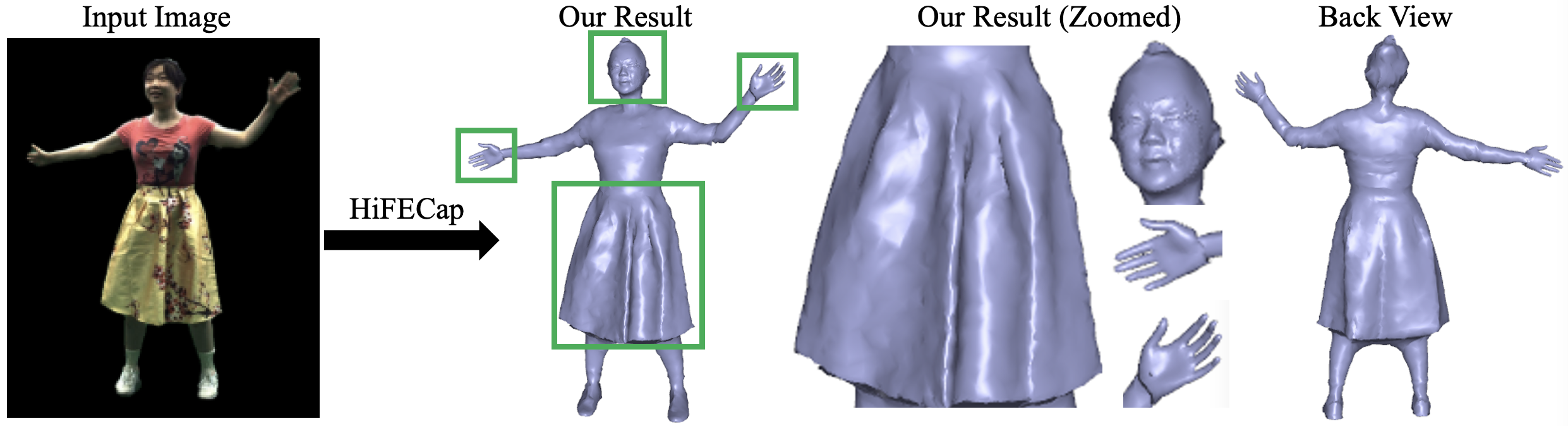 |
HiFECap: Monocular High-Fidelity and Expressive Capture of Human Performances
Yue Jiang
Marc Habermann
Vladislav Golyanik
Christian Theobalt
BMVC 2022
AbstractMonocular 3D human performance capture is indispensable for many applications in computer graphics and vision for enabling immersive experiences. However, detailed capture of humans requires tracking of multiple aspects, including the skeletal pose, the dynamic surface, which includes clothing, hand gestures as well as facial expressions. No existing monocular method allows joint tracking of all these components. To this end, we propose HiFECap, a new neural human performance capture approach, which simultaneously captures human pose, clothing, facial expression, and hands just from a single RGB video. We demonstrate that our proposed network architecture, the carefully designed training strategy, and the tight integration of parametric face and hand models to a template mesh enable the capture of all these individual aspects. Importantly, our method also captures high-frequency details, such as deforming wrinkles on the clothes, better than the previous works. Furthermore, we show that HiFECap outperforms the state-of-the-art human performance capture approaches qualitatively and quantitatively while for the first time capturing all aspects of the human.
|
 |
Neural Radiance Transfer Fields for Relightable Novel-view Synthesis with Global Illumination
Linjie Lyu
Ayush Tewari
Thomas Leimkühler
Marc Habermann
Christian Theobalt
ECCV 2022 (Oral)
AbstractGiven a set of images of a scene, the re-rendering of this scene from novel views and lighting conditions is an important and challenging problem in Computer Vision and Graphics. On the one hand, most existing works in Computer Vision usually impose many assumptions regarding the image formation process, e.g. direct illumination and predefined materials, to make scene parameter estimation tractable. On the other hand, mature Computer Graphics tools allow modeling of complex photo-realistic light transport given all the scene parameters. Combining these approaches, we propose a method for scene relighting under novel views by learning a neural precomputed radiance transfer function, which implicitly handles global illumination effects using novel environment maps. Our method can be solely supervised on a set of real images of the scene under a single unknown lighting condition. To disambiguate the task during training, we tightly integrate a differentiable path tracer in the training process and propose a combination of a synthesized OLAT and a real image loss. Results show that the recovered disentanglement of scene parameters improves significantly over the current state of the art and, thus, also our re-rendering results are more realistic and accurate.
|
 |
Physical Inertial Poser (PIP): Physics-aware Real-time Human Motion Tracking from Sparse Inertial Sensors
Xinyu Yi
Yuxiao Zhou
Marc Habermann
Soshi Shimada
Vladislav Golyanik
Christian Theobalt Feng Xu CVPR 2022 Best Paper Candidate (1.6% of accepted papers) AbstractMotion capture from sparse inertial sensors has shown great potential compared to image-based approaches since occlusions do not lead to a reduced tracking quality and the recording space is not restricted to be within the viewing frustum of the camera. However, capturing the motion and global position only from a sparse set of inertial sensors is inherently ambiguous and challenging. In consequence, recent state-of-the-art methods can barely handle very long period motions, and unrealistic artifacts are common due to the unawareness of physical constraints. To this end, we present the first method which combines a neural kinematics estimator and a physics-aware motion optimizer to track body motions with only 6 inertial sensors. The kinematics module first regresses the motion status as a reference, and then the physics module refines the motion to satisfy the physical constraints. Experiments demonstrate a clear improvement over the state of the art in terms of capture accuracy, temporal stability, and physical correctness.
|
2021
 |
Real-time Human Performance Capture and Synthesis
Marc Habermann
PhD Thesis 2021
Otto Hahn Medal 2022
Eurographics PhD Award 2022
DAGM MVTec Dissertation Award 2022
AbstractMost of the images one finds in the media, such as on the Internet or in textbooks and magazines, contain humans as the main point of attention. Thus, there is an inherent necessity for industry, society, and private persons to be able to thoroughly analyze and synthesize the human-related content in these images. One aspect of this analysis and subject of this thesis is to infer the 3D pose and surface deformation, using only visual information, which is also known as human performance capture. This thesis proposes two monocular human performance capture methods, which for the first time allow the real-time capture of the dense deforming geometry as well as an unseen 3D accuracy for pose and surface deformations. At the technical core, this work introduces novel GPU-based and data-parallel optimization strategies in conjunction with other algorithmic design choices that are all geared towards real-time performance at high accuracy. Moreover, this thesis presents a new weakly supervised multi-view training strategy combined with a fully differentiable character representation that shows superior 3D accuracy. However, there is more to human-related Computer Vision than only the analysis of people in images. It is equally important to synthesize new images of humans in unseen poses and also from camera viewpoints that have not been observed in the real world. To this end, this thesis presents a method and ongoing work on character synthesis, which allow the synthesis of controllable photoreal characters that achieve motion- and view-dependent appearance effects as well as 3D consistency and which run in real time. This is technically achieved by a novel coarse-to-fine geometric character representation for efficient synthesis, which can be solely supervised on multi-view imagery.
|
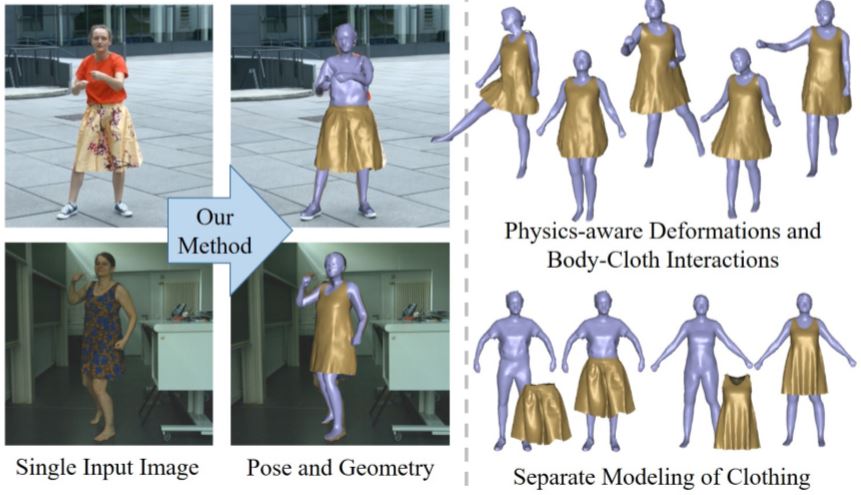 |
Deep Physics-aware Inference of Cloth Deformation for Monocular Human Performance Capture
Yue Li
Marc Habermann
Bernhard Thomaszewski
Stelian Coros
Thabo Beeler
Christian Theobalt
3DV 2021
AbstractRecent monocular human performance capture approaches have shown compelling dense tracking results of the full body from a single RGB camera. However, existing methods either do not estimate clothing at all or model cloth deformation with simple geometric priors instead of taking into account the underlying physical principles. This leads to noticeable artifacts in their reconstructions, such as baked-in wrinkles, implausible deformations that seemingly defy gravity, and intersections between cloth and body. To address these problems, we propose a person-specific, learning-based method that integrates a finite element-based simulation layer into the training process to provide for the first time physics supervision in the context of weakly-supervised deep monocular human performance capture. We show how integrating physics into the training process improves the learned cloth deformations, allows modeling clothing as a separate piece of geometry, and largely reduces cloth-body intersections. Relying only on weak 2D multi-view supervision during training, our approach leads to a significant improvement over current state-of-the-art methods and is thus a clear step towards realistic monocular capture of the entire deforming surface of a clothed human.
|
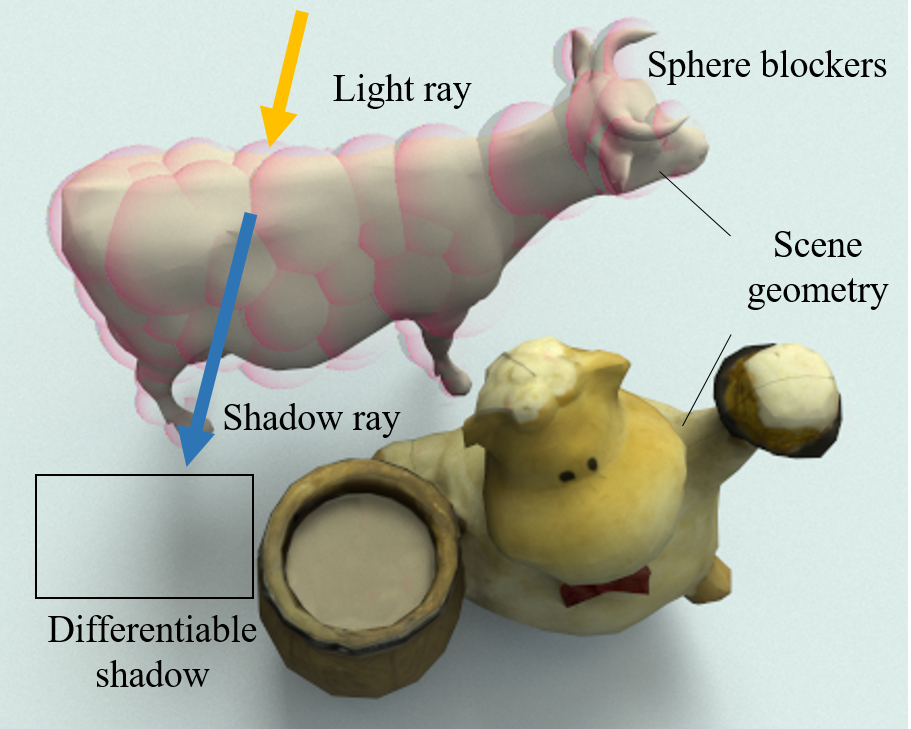 |
Efficient and Differentiable Shadow Computation for Inverse Problems
Linjie Lyu
Marc Habermann
Lingjie Liu
Mallikarjun B R
Ayush Tewari Christian Theobalt ICCV 2021 AbstractDifferentiable rendering has received increasing interest for image-based inverse problems. It can benefit traditional optimization-based solutions to inverse problems, but also allows for self-supervision of learning-based approaches for which training data with ground truth annotation is hard to obtain. However, existing differentiable renderers either do not model visibility of the light sources from the different points in the scene, responsible for shadows in the images, or are too slow for being used to train deep architectures over thousands of iterations. To this end, we propose an accurate yet efficient approach for differentiable visibility and soft shadow computation. Our approach is based on the spherical harmonics approximations of the scene illumination and visibility, where the occluding surface is approximated with spheres. This allows for a significantly more efficient shadow computation compared to methods based on ray tracing. As our formulation is differentiable, it can be used to solve inverse problems such as texture, illumination, rigid pose, and geometric deformation recovery from images using analysis-by-synthesis optimization.
|
 |
A Deeper Look into DeepCap
Marc Habermann
Weipeng Xu
Michael Zollhoefer
Gerard Pons-Moll
Christian Theobalt
TPAMI 2021
Invited Paper
AbstractHuman performance capture is a highly important computer vision problem with many applications in movie production and virtual/augmented reality. Many previous performance capture approaches either required expensive multi-view setups or did not recover dense space-time coherent geometry with frame-to-frame correspondences. We propose a novel deep learning approach for monocular dense human performance capture. Our method is trained in a weakly supervised manner based on multi-view supervision completely removing the need for training data with 3D ground truth annotations. The network architecture is based on two separate networks that disentangle the task into a pose estimation and a non-rigid surface deformation step. Extensive qualitative and quantitative evaluations show that our approach outperforms the state of the art in terms of quality and robustness. This work is an extended version of DeepCap where we provide more detailed explanations, comparisons and results as well as applications.
|
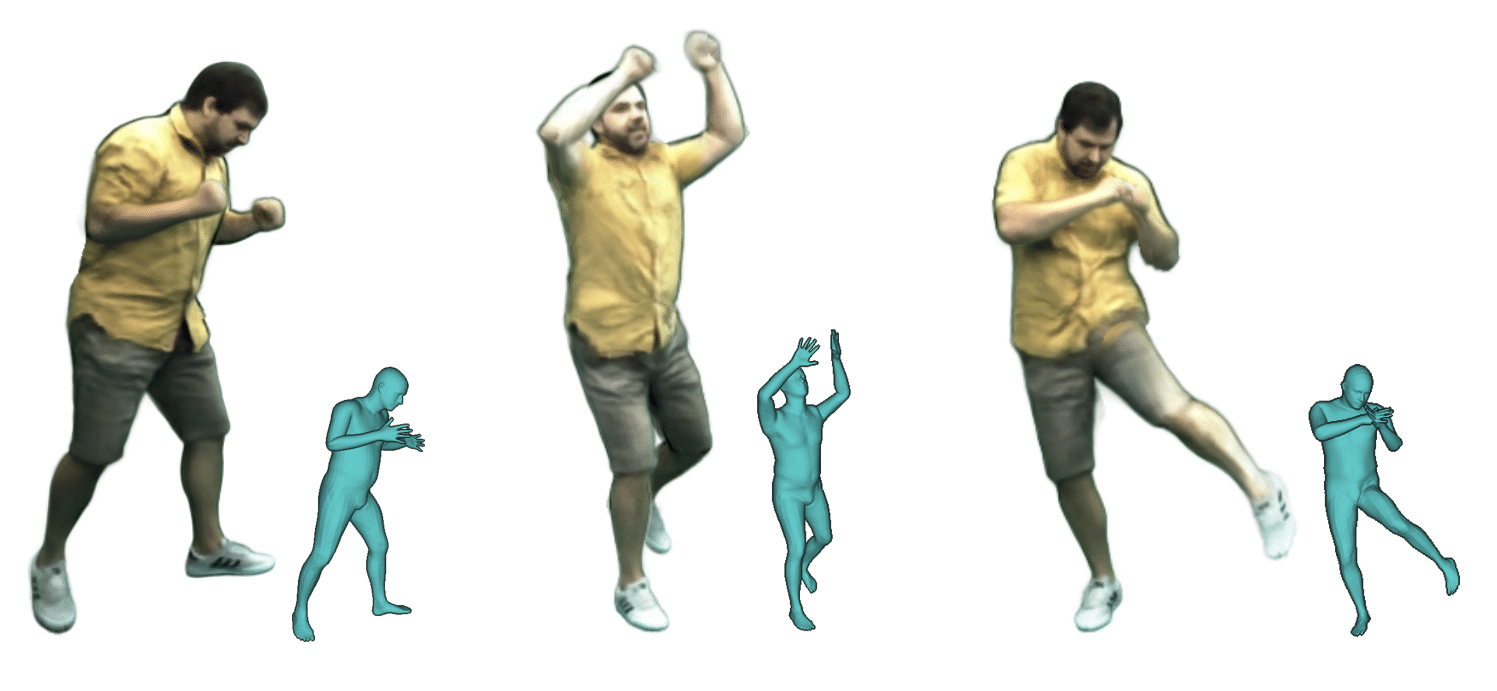 |
Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control
Lingjie Liu
Marc Habermann
Viktor Rudnev
Kripasindhu Sarkar
Jiatao Gu Christian Theobalt SIGGRAPH Asia 2021 AbstractWe propose Neural Actor (NA), a new method for high-quality synthesis of humans from arbitrary viewpoints and under arbitrary controllable poses. Our method is built upon recent neural scene representation and rendering works which learn representations of geometry and appearance from only 2D images. While existing works demonstrated compelling rendering of static scenes and playback of dynamic scenes, photo-realistic reconstruction and rendering of humans with neural implicit methods, in particular under user-controlled novel poses, is still difficult. To address this problem, we utilize a coarse body model as the proxy to unwarp the surrounding 3D space into a canonical pose. A neural radiance field learns pose-dependent geometric deformations and pose- and view-dependent appearance effects in the canonical space from multi-view video input. To synthesize novel views of high fidelity dynamic geometry and appearance, we leverage 2D texture maps defined on the body model as latent variables for predicting residual deformations and the dynamic appearance. Experiments demonstrate that our method achieves better quality than the state-of-the-arts on playback as well as novel pose synthesis, and can even generalize well to new poses that starkly differ from the training poses. Furthermore, our method also supports body shape control of the synthesized results.
|
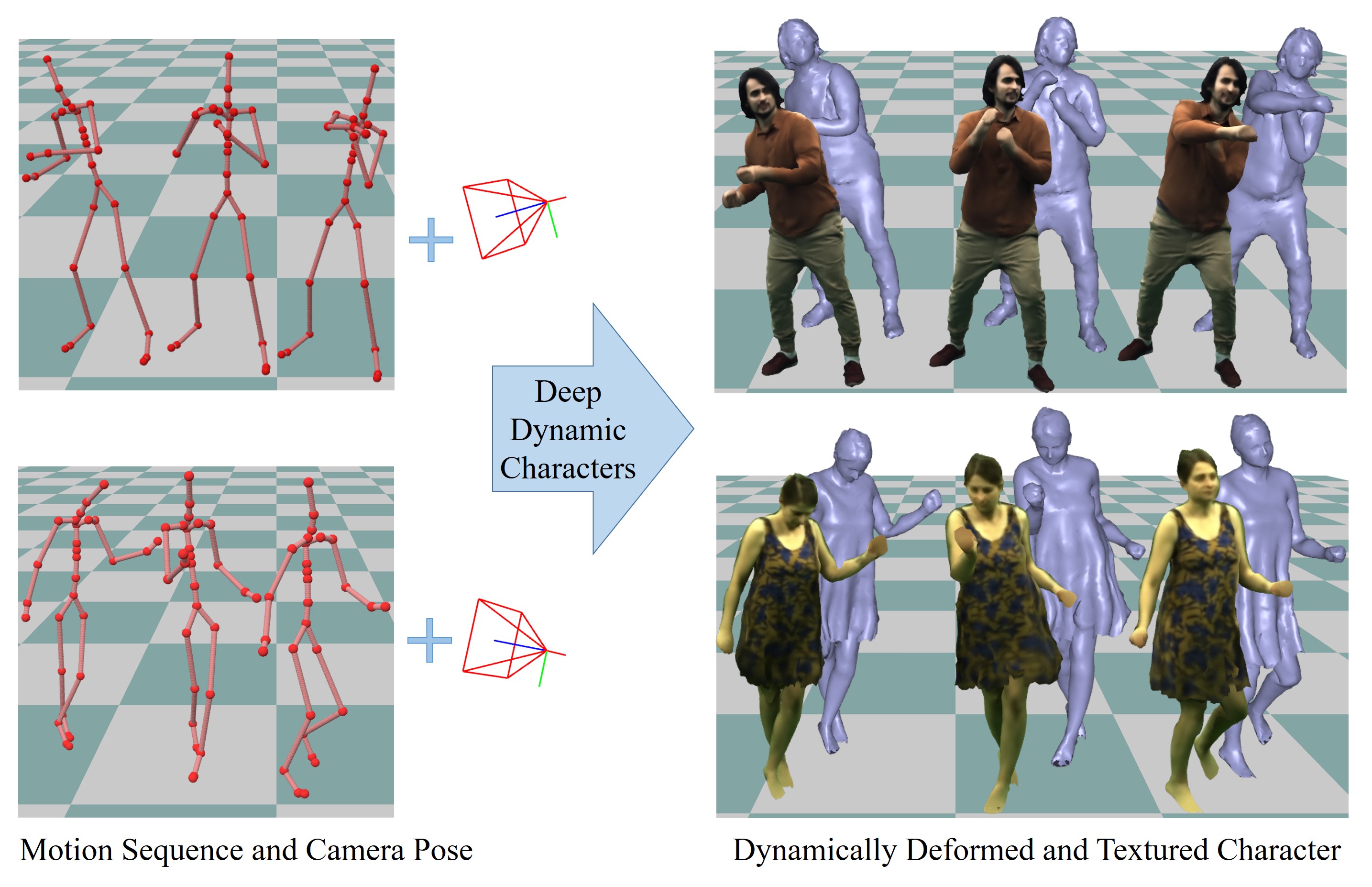 |
Real-time Deep Dynamic Characters
Marc Habermann
Lingjie Liu
Weipeng Xu
Michael Zollhoefer
Gerard Pons-Moll
Christian Theobalt
SIGGRAPH 2021
AbstractWe propose a deep videorealistic 3D human character model displaying highly realistic shape, motion, and dynamic appearance learned in a new weakly supervised way from multi-view imagery. In contrast to previous work, our controllable 3D character displays dynamics, e.g., the swing of the skirt, dependent on skeletal body motion in an efficient data-driven way, without requiring complex physics simulation. Our character model also features a learned dynamic texture model that accounts for photo-realistic motion-dependent appearance details, as well as view-dependent lighting effects. During training, we do not need to resort to difficult dynamic 3D capture of the human; instead we can train our model entirely from multi-view video in a weakly supervised manner. To this end, we propose a parametric and differentiable character representation which allows us to model coarse and fine dynamic deformations, e.g., garment wrinkles, as explicit space-time coherent mesh geometry that is augmented with high-quality dynamic textures dependent on motion and view point. As input to the model, only an arbitrary 3D skeleton motion is required, making it directly compatible with the established 3D animation pipeline. We use a novel graph convolutional network architecture to enable motion-dependent deformation learning of body and clothing, including dynamics, and a neural generative dynamic texture model creates corresponding dynamic texture maps. We show that by merely providing new skeletal motions, our model creates motion-dependent surface deformations, physically plausible dynamic clothing deformations, as well as video-realistic surface textures at a much higher level of detail than previous state of the art approaches, and even in real-time.
|
 |
Monocular Real-time Full Body Capture with Inter-part Correlations
Yuxiao Zhou
Marc Habermann
Ikhsanul Habibie
Ayush Tewari
Christian Theobalt Feng Xu CVPR 2021 AbstractWe present the first method for real-time full body capture that estimates shape and motion of body and hands together with a dynamic 3D face model from a single color image. Our approach uses a new neural network architecture that exploits correlations between body and hands at high computational efficiency. Unlike previous works, our approach is jointly trained on multiple datasets focusing on hand, body or face separately, without requiring data where all the parts are annotated at the same time, which is much more difficult to create at sufficient variety. The possibility of such multi-dataset training enables superior generalization ability. In contrast to earlier monocular full body methods, our approach captures more expressive 3D face geometry and color by estimating the shape, expression, albedo and illumination parameters of a statistical face model. Our method achieves competitive accuracy on public benchmarks, while being significantly faster and providing more complete face reconstructions.
|
2020
 |
Differentiable Rendering Tool
Marc Habermann
Mallikarjun B R
Ayush Tewari
Linjie Lyu
Christian Theobalt
Github
AbstractThis is a simple and efficient differentiable rasterization-based renderer which has been used in several GVV publications. The implementation is free of most third-party libraries such as OpenGL. The core implementation is in CUDA and C++. We use the layer as a custom Tensorflow op. The renderer supports the following features:
|
 |
DeepCap: Monocular Human Performance Capture Using Weak Supervision
Marc Habermann
Weipeng Xu
Michael Zollhoefer
Gerard Pons-Moll
Christian Theobalt
CVPR 2020 (Oral)
CVPR 2020 Best Student Paper Honorable Mention
AbstractHuman performance capture is a highly important computer vision problem with many applications in movie production and virtual/augmented reality. Many previous performance capture approaches either required expensive multi-view setups or did not recover dense space-time coherent geometry with frame-to-frame correspondences. We propose a novel deep learning approach for monocular dense human performance capture. Our method is trained in a weakly supervised manner based on multi-view supervision completely removing the need for training data with 3D ground truth annotations. The network architecture is based on two separate networks that disentangle the task into a pose estimation and a non-rigid surface deformation step. Extensive qualitative and quantitative evaluations show that our approach outperforms the state of the art in terms of quality and robustness.
|
 |
Neural Human Video Rendering by Learning Dynamic Textures and Rendering-to-Video Translation
Lingjie Liu
Weipeng Xu
Marc Habermann
Michael Zollhoefer
Florian Bernard
Hyeongwoo Kim
Wenping Wang
Christian Theobalt
TVCG 2020
AbstractSynthesizing realistic videos of humans using neural networks has been a popular alternative to the conventional graphics-based rendering pipeline due to its high efficiency. Existing works typically formulate this as an image-to-image translation problem in 2D screen space, which leads to artifacts such as over-smoothing, missing body parts, and temporal instability of fine-scale detail, such as pose-dependent wrinkles in the clothing. In this paper, we propose a novel human video synthesis method that approaches these limiting factors by explicitly disentangling the learning of time-coherent fine-scale details from the embedding of the human in 2D screen space. More specifically, our method relies on the combination of two convolutional neural networks (CNNs). Given the pose information, the first CNN predicts a dynamic texture map that contains time-coherent high-frequency details, and the second CNN conditions the generation of the final video on the temporally coherent output of the first CNN. We demonstrate several applications of our approach, such as human reenactment and novel view synthesis from monocular video, where we show significant improvement over the state of the art both qualitatively and quantitatively.
|
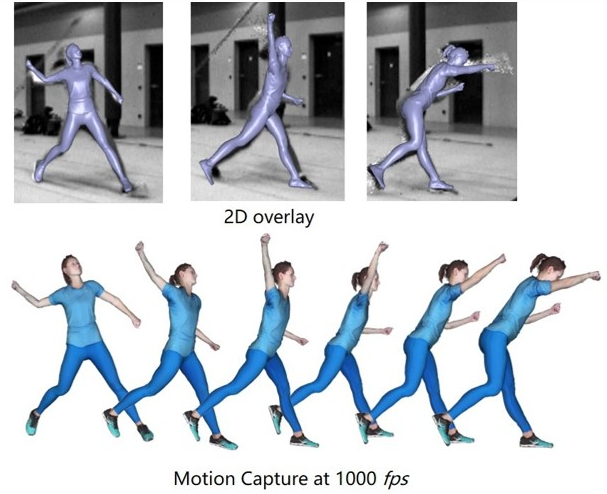 |
EventCap: Monocular 3D Capture of High-Speed Human Motions using an Event Camera
Lan Xu
Weipeng Xu
Vladislav Golyanik
Marc Habermann
Lu Fang
Christian Theobalt
CVPR 2020 (Oral)
AbstractThe high frame rate is a critical requirement for capturing fast human motions. In this setting, existing markerless image-based methods are constrained by the lighting requirement, the high data bandwidth and the consequent high computation overhead. In this paper, we propose EventCap — the first approach for 3D capturing of high-speed human motions using a single event camera. Our method combines model-based optimization and CNN-based human pose detection to capture high-frequency motion details and to reduce the drifting in the tracking. As a result, we can capture fast motions at millisecond resolution with significantly higher data efficiency than using highframe rate videos. Experiments on our new event-based fast human motion dataset demonstrate the effectiveness and accuracy of our method, as well as its robustness to challenging lighting conditions.
|
 |
Monocular Real-time Hand Shape and Motion Capture using Multi-modal Data
Yuxiao Zhou
Marc Habermann
Weipeng Xu
Ikhsanul Habibie
Christian Theobalt Feng Xu CVPR 2020 AbstractWe present a novel method for monocular hand shape and pose estimation at unprecedented runtime performance of 100fps and at state-of-the-art accuracy. This is enabled by a new learning based architecture designed such that it can make use of all the sources of available hand training data: image data with either 2D or 3D annotations, as well as stand-alone 3D animations without corresponding image data. It features a 3D hand joint detection module and an inverse kinematics module which regresses not only 3D joint positions but also maps them to joint rotations in a single feed-forward pass. This output makes the method more directly usable for applications in computer vision and graphics compared to only regressing 3D joint positions. We demonstrate that our architectural design leads to a significant quantitative and qualitative improvement over the state of the art on several challenging benchmarks. We will make our code publicly available for future research.
|
2019
 |
LiveCap: Real-time Human Performance Capture from Monocular Video
Marc Habermann
Weipeng Xu
Michael Zollhoefer
Gerard Pons-Moll
Christian Theobalt
ACM ToG 2019 @ SIGGRAPH 2019
AbstractWe present the first real-time human performance capture approach that reconstructs dense, space-time coherent deforming geometry of entire humans in general everyday clothing from just a single RGB video.We propose a novel two-stage analysis-by-synthesis optimization whose formulation and implementation are designed for high performance. In the first stage, a skinned template model is jointly fitted to background subtracted input video, 2D and 3D skeleton joint positions found using a deep neural network, and a set of sparse facial landmark detections. In the second stage, dense non-rigid 3D deformations of skin and even loose apparel are captured based on a novel real-time capable algorithm for non-rigid tracking using dense photometric and silhouette constraints. Our novel energy formulation leverages automatically identified material regions on the template to model the differing non-rigid deformation behavior of skin and apparel. The two resulting nonlinear optimization problems per-frame are solved with specially-tailored data-parallel Gauss-Newton solvers. In order to achieve real-time performance of over 25Hz, we design a pipelined parallel architecture using the CPU and two commodity GPUs. Our method is the first real-time monocular approach for full-body performance capture. Our method yields comparable accuracy with off-line performance capture techniques, while being orders of magnitude faster.
|
 |
Neural Animation and Reenactment of Human Actor Videos
Lingjie Liu
Weipeng Xu
Michael Zollhoefer
Hyeongwoo Kim
Florian Bernard Marc Habermann Wenping Wang Christian Theobalt ACM ToG 2019 @ SIGGRAPH 2019 AbstractWe propose a method for generating (near) video-realistic animations of real humans under user control. In contrast to conventional human character rendering, we do not require the availability of a production-quality photo-realistic 3D model of the human, but instead rely on a video sequence in conjunction with a (medium-quality) controllable 3D template model of the person. With that, our approach significantly reduces production cost compared to conventional rendering approaches based on production-quality 3D models, and can also be used to realistically edit existing videos. Technically, this is achieved by training a neural network that translates simple synthetic images of a human character into realistic imagery. For training our networks, we first track the 3D motion of the person in the video using the template model, and subsequently generate a synthetically rendered version of the video. These images are then used to train a conditional generative adversarial network that translates synthetic images of the 3D model into realistic imagery of the human. We evaluate our method for the reenactment of another person that is tracked in order to obtain the motion data, and show video results generated from artist-designed skeleton motion. Our results outperform the state-of-the-art in learning-based human image synthesis.
|
2018
 |
NRST: Non-rigid Surface Tracking from Monocular Video
Marc Habermann
Weipeng Xu
Helge Rhodin
Michael Zollhoefer
Gerard Pons-Moll
Christian Theobalt
Oral @ German Conference on Pattern Recognition (GCPR) 2018
AbstractWe propose an efficient method for non-rigid surface tracking from monocular RGB videos. Given a video and a template mesh, our algorithm sequentially registers the template non-rigidly to each frame.We formulate the per-frame registration as an optimization problem that includes a novel texture term specifically tailored towards tracking objects with uniform texture but fine-scale structure, such as the regular micro-structural patterns of fabric. Our texture term exploits the orientation information in the micro-structures of the objects, e.g., the yarn patterns of fabrics. This enables us to accurately track uniformly colored materials that have these high frequency micro-structures, for which traditional photometric terms are usually less effective. The results demonstrate the effectiveness of our method on both general textured non-rigid objects and monochromatic fabrics.
|
Awards & Honors
- August 2023
SCA 2023 Best Paper Award Honorable Mention, Los Angeles, USA - June 2023
Otto Hahn Medal 2022, Goettingen, Germany - September 2022
DAGM MVTec Dissertation Award 2022, Konstanz, Germany - April 2022
Eurographics PhD Award 2022, Reims, France - June 2020
CVPR 2020 Best Student Paper Honorable Mention, Seattle, USA - November 2017
Günter-Hotz-Medal for the best Master graduates in Computer Science, Saarbrücken, Germany
Education & Recent Positions
- December 2024 - now
Tenured senior researcher at the Max Planck Institute for Informatics, Saarbrücken, Germany - November 2021 - now
Scientific manager of the Real Virtual Lab at the Max Planck Institute for Informatics, Saarbrücken, Germany - January 2024 - December 2024
Tenured research group leader at the Max Planck Institute for Informatics, Saarbrücken, Germany - November 2021 - December 2023
Research group leader at the Max Planck Institute for Informatics, Saarbrücken, Germany - October 2021
Dr.-Ing. (PhD) degree in Computer Science, Max Planck Institute for Informatics / Saarland University, Saarbrücken, Germany - September 2017 - October 2021
PhD student at the Max Planck Institute for Informatics in the Visual Computing and Artificial Intelligence Department, Saarbrücken, Germany - April 2016 - November 2017
Master Studies in Computer Science at Saarland University, Saarbrücken, Germany
Title of Master's Thesis (Diplomarbeit): RONDA - Reconstruction of Non-rigid Surfaces from High Resolution Video (supervisor: Prof. Dr. Christian Theobalt) (PDF) - October 2012 - April 2016:
Bachelor Studies in Computer Science at Saarland University, Saarbrücken, Germany
Title of Bachelor's Thesis: Drone Path Planning (supervisor: Dr.-Ing. Tobias Ritschel) (PDF) - July 2012:
Abitur at the Albertus Magnus Gymnasium, Sankt Ingbert, Germany
Teaching
- October 2024 - February 2025
Lecturer for Advanced Topics in Neural Rendering and Reconstruction, Lecturer: Prof. Dr. Christian Theobalt, Dr. Rishabh Dabral, Dr. Vladislav Golyanik, Dr. Thomas Leimkühler, Dr. Marc Habermann at the Saarland University, Saarbrücken, Germany - April 2024 - August 2024
Lecturer for Classical Concepts of Computer Vision and Computer Graphics in the Neural Age, Lecturer: Prof. Dr. Christian Theobalt, Dr. Marc Habermann, Dr. Thomas Leimkühler, Dr. Rishabh Dabral at the Saarland University, Saarbrücken, Germany - October 2023 - February 2024
Lecturer for Advanced Topics in Neural Rendering and Reconstruction, Lecturer: Prof. Dr. Christian Theobalt, Dr. Mohamed Elgharib, Dr. Vladislav Golyanik, Dr. Thomas Leimkühler, Dr. Marc Habermann at the Saarland University, Saarbrücken, Germany - April 2022 - August 2022
Lecturer for Computer Vision and Machine Learning for Computer Graphics, Lecturer: Prof. Dr. Christian Theobalt, Dr. Marc Habermann, Dr. Thomas Leimkühler at the Saarland University, Saarbrücken, Germany - April 2021 - August 2021
Supervisor for Computer Vision and Machine Learning for Computer Graphics, Lecturer: Prof. Dr. Christian Theobalt, Dr. Mohamed Elgharib, Dr. Vladislav Golyanik at the Saarland University, Saarbrücken, Germany - April 2020 - August 2020
Supervisor for Computer Vision and Machine Learning for Computer Graphics, Lecturer: Prof. Dr. Christian Theobalt, Dr. Mohamed Elgharib, Dr. Vladislav Golyanik at the Saarland University, Saarbrücken, Germany - April 2019 - August 2019
Supervisor for Computer Vision and Machine Learning for Computer Graphics, Lecturer: Prof. Dr. Christian Theobalt, Dr. Mohamed Elgharib, Dr. Vladislav Golyanik at the Saarland University, Saarbrücken, Germany - April 2018 - August 2018
Supervisor for 3D Shape Analysis, Lecturer: Dr. Florian Bernard and Prof. Dr. Christian Theobalt at the Saarland University, Saarbrücken, Germany - September 2016 - June 2018
Tutor for Seminarfach 3D Modellierung at the Leibniz Gymnasium/Albertus Magnus Gymnasium, Sankt Ingbert, Germany - July 2013 - September 2016:
Tutor for 3D Modellierung Alte Schmelz, Sankt Ingbert, Germany
Community Service
I served as an area chair for the following conferences:
- 3DV (2025, 2026)
I served as an associate editor for the following journals:
- TVCG (since 2025)
I also regularly serve as reviewer for the following conferences and journals:
- SIGGRAPH
- SIGGRAPH Asia
- CVPR
- ECCV
- CRV
- ToG
- TPAMI
- IJCV
- TVCG
- TCSVT
- CVIU
- PG
- 3DV
- Neurips
Private
Hobbies
- Photography
- Bouldering
- Reading Books